운영체제를 처음 공부할 때는 폴링은 디바이스가 작업을 완료하기까지 대기하는 게 시간낭비이므로, IO가 무조건 인터럽트 방식으로 이루어질 거라고 생각했다. 하지만 하드웨어 성능이 미친듯이 좋아지면서 오히려 인터럽트의 오버헤드가 성능에 큰 영향을 미치기도 한다. When Poll is Better than Interrupt는 2012년에 USENIX에서 발표된 논문으로 고성능 디바이스에서 폴링이 인터럽트 방식보다 나을 수 있음을 보여준다. 실제로 블록 레이어에서는 2015년에 폴링 방식이 구현되었다. 네트워크 레이어는 훨씬 더 전인 2000년대 초반부터 NAPI를 통해 폴링을 지원했다.
When Poll Is Better than Interrupt | USENIX
www.usenix.org
Abstract
전통적인 I/O 요청을 처리할 때는 모든 I/O를 인터럽트를 통해 비동기로 처리한다. 하지만 latency가 엄청 낮은 차세대 Non-Volatile Memory 디바이스를 사용한다면 전통적인 인터럽트 방식의 I/O보다 나은 성능을 보여준다. 물론 I/O를 처리하는 동안 CPU 사이클을 낭비하기는 하지만 말이다. 이 논문에서는 1) 동기 I/O 완료 모델이 보여주는 지연 시간에서의 이점과 2) 현재의 인터럽트 방식에서의 I/O 처리 방식을 묘사하고 3) 동기적으로 I/O 요청을 처리하는 (Synchronous Completion) 방식이 올바르고 안전하다는 것을 보임으로써 동기적인 I/O 처리 방식을 제안한다. 그리고 더 나아가 운영체제와 어플리케이션에서 동기적인 처리 방식의 도전적인 과제들에 대해서 논의한다.
Introduction
운영체제가 블록 스토리지 I/O 요청을 처리할 때는 일반적으로 비동기적으로 처리한다. 이렇게 함으로써 디바이스가 I/O를 처리할 때까지 기다리는 대신, 다른 태스크를 처리할 수가 있다. 따라서 CPU 사이클을 디바이스를 대기하느라 낭비하지 않아도 될 뿐만 아니라, I/O 스케줄러에서 I/O 요청을 병합하고 순서를 조정하기도 한다. 실제로 하드 디스크는 랜덤 액세스 성능이 떨어지므로 현재 헤드 근처의 I/O 요청을 처리하도록 I/O 요청을 스케줄링하는 것이 성능에 큰 영향을 미쳤다. 그리고 실제로 비동기 I/O 처리 방식은 하드 디스크나 NAND기반 SSD에서도 잘 돌아갔다.

하지만 미래의 SSD 디바이스는 차세대 NVM 기술을 더욱 잘 활용할 것이다. 이 논문이 2012년에 발표되었다는 걸 감안해보자. 당시에는 SSD가 약 수천개~수만개의 IOPS (I/O Operations Per Second) 정도밖에 처리하지 못했다. 지금 Samsung 980 Pro 500GB가 1M IOPS, Intel Optane DC P5800x가 150M IOPS의 성능을 자랑한다는 걸 생각해보면 성능이 정말 미친듯이 올랐다는 걸 체감할 수 있다. (물론 P5800x는 개인이 사기엔 좀 비싸다. 980이 그나마 살만하다.)


그리고 여담이지만 최근 들어 블록 레이어에서는 최근에 리눅스 5.15~5.16 개발 주기동안 폴링 방식의 성능을 약 3.5M IOPS에서 10M IOPS까지 코어당 성능을 끌어올리고 있다.
무튼 최근 동향은 여기까지 알아보도록 하고 다시 논문으로 돌아가자.
이 논문에서는 동기적인 I/O 완료 모델은 I/O를 요청한 프로세스 컨텍스트 내에서 처리된다는 점을 근거로 동기적인 방식이 더 낫다고 주장한다. 인터럽트 방식의 비동기 처리 모델에서는 I/O를 요청한 프로세스의 컨텍스트와, I/O를 실제로 요청하는 컨텍스트, I/O 요청이 완료되었을 때의 컨텍스트가 모두 다르기 때문에 컨텍스트를 전환하는 오버헤드가 발생한다. 반면 동기적인 I/O 완료 모델은 I/O를 요청한 프로세스 컨텍스트 내에서 요청을 하는 것부터 끝나기 까지 모든 것을 처리한다. 단, 동기적인 방식에서는 디바이스가 I/O 처리를 완료할 때까지 기다려야한다 (spin-wait). 기다리는 동안은 아무것도 할 수 없다.
이 논문이 쓰여질 당시에는 SSD의 성능도 그렇게 좋지 못했기 때문에, DRAM 기반 스토리지 디바이스로 차세대 SSD를 시뮬레이션한다.
인터럽트 기반의 비동기 완료 모델은 매우 빠른 SSD에서 성능 이슈가 생긴다. 비동기 방식은 스레드가 많아졌을 때도 낮은 I/O 처리율을 보여준다. 이 논문에서는 실제로 리눅스에서 이러한 성능 이슈가 있었다는 점을 보여주고, 인터럽트 핸들링, 캐시 오염, CPU power-state transition의 오버헤드를 측정한다. 또한 동기적인 모델이 간단하고 올바르며 non-blocking I/O나 multi-threading에서도 잘 작동한다는 것을 보여준다.
이 논문에서는 어플리케이션이 Non-blocking I/O, 그리고 I/O prefetching과 같은 버퍼링 전략을 재평가 함으로써 개선될 수 있다고 제안한다. 그리고 우리는 미래의 SSD가 차세대 NVM 구성요소로 만들어진다고 가정하고 동기 모델이 성능상의 큰 개선을 할 수 있음을 보여준다.
Background
NVM 기술의 발전으로 인한 SSD의 상업적인 성공으로 대용량 스토리지와 메모리 간의 성능 격차가 매우 줄어들었다. [15] 또한 I/O 요청을 몇 us 안에 처리하는 실험적인 스토리지 디바이스도 증명이 되었다. [8] 이러한 트렌드로 인해 I/O 스택에서 소모하는 시간이 더 중요해진다. [8, 12]. 또한 이러한 트렌드로 더 이상 하드디스크에서처럼 순차적인 여러 개의 I/O 요청을 병합해서 거대하게 만드는 것보다, 작은 I/O 요청을 랜덤하게 처리해도 될 정도로 성능이 좋아졌다. [17]
전통적인 블록 레이어의 I/O 구조에서는 운영체제의 블록 I/O 서브시스템이 I/O 요청을 스케줄링하고 블록 디바이스로 보내는 방식으로 I/O를 처리했다. 이때 이 서브시스템은 커널 I/O 요청에 디스크 섹터, 메모리 주소, I/O 요청의 크기, 파일, 페이지 캐시 등을 명시해서 처리한다. 블록 I/O 서브시스템은 커널 I/O 요청을 커널 I/O 큐에 넣은 후 I/O를 요청한 스레드는 I/O를 기다리는 상태로 전환하여 휴면 상태가 된다. 그 다음 I/O 디바이스가 이를 처리한다. 그러면 디바이스는 커널 I/O 요청을 디바이스 I/O 커맨드(디바이스에 의존적임)로 변환해서 처리한다.
I/O 커맨드의 처리를 끝내고 나면 스토리지 디바이스는 요청이 끝났음을 알리기 위해 하드웨어 인터럽트를 발생한다. 그러면 블록 I/O 서브시스템은 I/O 요청을 종료하고 I/O를 기다리던 스레드를 깨운다. 스토리지 디바이스는 자신만의 디바이스 큐를 통해서 디바이스 I/O 커맨드를 동시에 여러 개를 처리할 수 있다. [2,5,6] 그리고 하드웨어 인터럽트의 오버헤드를 줄이기 위해 인터럽트도 병합할 수 있다.
아까 말했듯 전통적인 블록 I/O 서브시스템은 CPU 사이클을 절약하기 위해서 비동기적인 방식을 사용한다. 그렇게 함으롰 디바이스가 I/O를 처리하는 동안 CPU는 다른 일을 할 수가 있다. 또한 I/O 스케줄러는 여러 개의 I/O 요청을 병합해서 속도를 향상한다. 이러한 방식은 비동기 I/O 완료 모델이라고 할 수 있다.
이 모델에서는 I/O를 요청한 프로세스의 컨텍스트, 실제로 I/O 요청을 보내는 커널 코드의 컨텍스트, 그리고 I/O 요청 완료시 발생하는 인터럽트 컨텍스트 등 다양한 컨텍스트를 오가기 때문에 오버헤드가 존재한다. 모든 것이 끝나면 다시 I/O를 요청한 프로세스의 컨텍스트로 돌아간다. 따라서 I/O 요청 하나를 처리할 때 적어도 3번의 컨텍스트 스위칭을 해야한다.
블록 I/O 서브시스템은 디바이스 드라이버를 위한 인터페이스를 제공한다. 리눅스에서는 블록 디바이스 드라이버는 인터럽트 컨텍스트에서 실행할 request_fn 함수를 정의해야 한다 [7, 10]. 또한 리눅스는 ramdisk같은 가상의 블록 디바이스에서 사용할 수 있는 make_request 콜백 함수도 제공한다.
Synchronous I/O completion model
프로세스가 I/O를 동기적으로 처리한다는 것은 I/O를 요청할 때부터 끝날 때까지 모든 것이 I/O를 요창한 프로세스의 컨텍스트 안에서 처리된다는 의미이다. 동기적인 모델을 구현하려면 반드시 CPU는 디바이스를 폴링해야한다. 또한 이 폴링은 spin-loop, busy-waiting 방식으로 작동해야 한다.
기존의 비동기적인 모델과 비교했을 때 동기적인 모델은 I/O 요청을 더 적은 CPU 사이클 안에 처리할 수 있다. CPU 사이클을 절약할 수 있는 이유는 인터럽트 핸들링과 컨텍스트 스위칭의 오버헤드를 없애기 때문이다. 대신 동기적인 모델에서는 폴링을 하느라 CPU 사이클을 사용한다. 이 절에서는 방금 언급한 몇가지 오버헤드를 측정할 것이다. 그 다음 비동기적인 모델의 문제점과 동기적인 모델이 올바르다는 것을 보여줄 것이다.
Prototype hardware and device driver
이 논문에서는 측정을 위해 NVM Express 인터페이스를 사용하는 블록 스토리지 디바이스를 사용한다 [5]. 이때 스토리지 디바이스는 차세대 NVM 기술을 사용하는 미래의 SSD를 시뮬레이션하기 위해 DRAM 기반 디바이스를 사용한다. NVM Express는 2011년에 표준이 생겼으므로 매우 초기 상태의 표준임을 참고하자.
이 디바이스는 PCIe Gen2 버스 위에서 동작한다. NVM Express의 표준에서 명시하는 것과 같이 메모리를 통해 디바이스 드라이버와 소통해서 디바이스 커맨드를 전송하고, 요청이 완료되었다는 것도 확인할 수 있다. 또한 이 디바이스는 자신만의 멀티 큐를 갖고 처리할 수 있다.
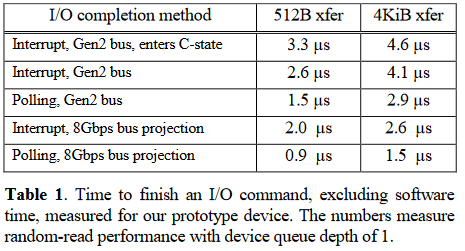
위의 표는 프로토타입 디바이스의 성능을 보여준다. 표에서 'C-state'는 CPU가 디바이스가 IO를 처리하는 동안 절전 모드로 전환되었을 때의 성능이다. 여기서 성능되는 측정은 실존하는 SSD가 아니라 DRAM 기반 프로토타입 디바이스의 성능에 제한된다. 따라서 여기서의 성능 측정은 미래의 SSD 성능이 더 개선될 것이라는 가정 하에 진행된다.
이 논문에서는 프로토타입 하드웨어에서 작동하는 동기적인 모델 / 비동기적인 모델을 지원하는 디바이스 드라이버를 각각 만든 후 성능을 측정한다. 비동기적인 모델에서는 request_fn 콜백 함수를 구현해서 전통적인 인터럽트 처리 방식을 구현한다. 이 모델에서는 드라이버가 하드웨어 인터럽트를 사용해서 IO의 요청과 완료를 모두 인터럽트 컨텍스트에서 처리한다.
동기적인 모델에서는 make_request 콜백 함수를 구현해서 기존의 블록 I/O 서브시스템을 건너뛰고 직접 I/O를 처리한다. 이 모델에서는 드라이버가 디바이스를 폴링해서 I/O 요청의 완료를 기다린다. 따라서 비동기적인 모델처럼 프로세스 컨텍스트와 인터럽트 컨텍스트를 왔다갔다 할 필요가 없다.
Experimental setup and methodology
이 논문에서는 x86 듀얼 소켓 서버, 12GB의 메모리 위해서 64비트 페도라 13 / 2.6.33 커널을 사용한다. 각각의 프로세서 소켓은 쿼드코어 2.93GHz Intel Xeon 프로세서를 사용한다. (8MB L3, 256KB L1) 그리고 Intel HyperThreading Technology가 활성화되어서 총 16개의 스레드를 사용할 수 있다. CPU frequency-scaling은 비활성화했다.
측정을 하기위해 여기서는 CPU 타임스탬프 카운터와 사용자 레벨의 프로그램에서 측정된 시간을 사용한다. 이때 인텔의 'rdtsc' 명령어로 CPU의 타임스탬프 카운터를 읽는다. 어플리케이션의 IOPS를 측정할 때는 사용자 모드에서 실행되는 fio [1] 벤치마크를 사용한다.
그리고 여기서는 블록 I/O 서브시스템에서 발생하는 비용과 모델의 성능을 분리하기 위해 파일시스템과 버퍼 캐시를 비활성화한다. 그리고 커널은 -O3 최적화 옵션을 사용하고 선점이 활성화되도록 컴파일되었다. 비동기적인 모델의 성능을 최대한 빠르게 하기 위해 'noop' 스케줄러를 사용해서 I/O 스케줄링을 하지 않도록 했다.
Storage stack latency comparison
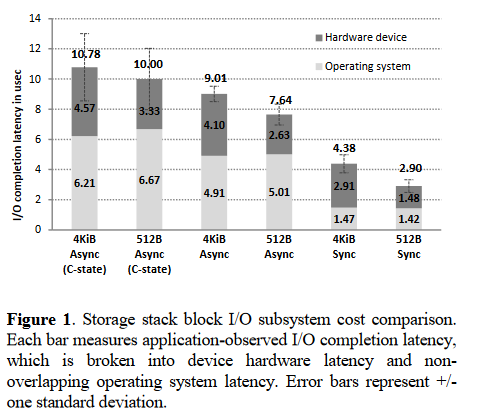
- 얼마나 어플리케이션의 요청을 빠르게 처리하는가?
- 각각의 모델에서 CPU 시간을 얼마나 소모했는가?
- 비동기적인 모델에서는 얼마만큼의 CPU 시간을 다른 프로세스가 사용할 수 있었는가?
위의 그래프는 동기적인 모델이 비동기적인 모델보다 절대적인 지연 시간 측면에서 더 빠르게 처리한다는 것을 보여준다. 위의 그래프는 4KB / 512B 사이즈의 요청을 처리할 때의 어플리케이션의 I/O 요청 지연 시간을 보여준다. 동기적인 모델에서는 4KB I/O를 4.4us만에 처리한 반면 비동기적인 모델에서는 7.6us만에 처리했다. 위 그림에서는 하드웨어에서 걸린 시간과 운영체제에서 걸린 시간을 나눠서 보여준다. 비동기 모델에서는 인터럽트를 처리하기 때문에 더 많은 시간이 소요된다.
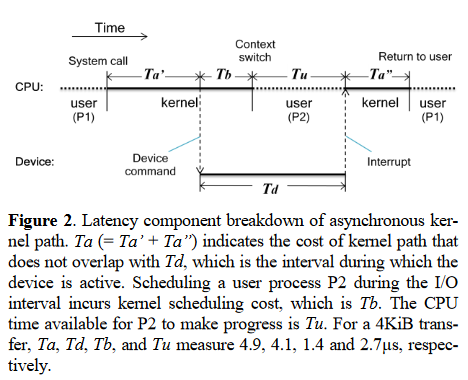
그림 2에서는 비동기 모델에서 걸리는 시간이 어디에 소요되냐에 따라 나눠서 보여준다. 이때 Tu는 디바이스가 I/O를 처리하는 동안 다른 프로세스가 CPU를 사용할 수 있는 시간이다. 이 시간을 정확하게 측정하기 위해 벤치마크를 돌리는 CPU에서 별도의 사용자 레벨 프로세스를 실행한다. 이 프로그램은 us 단위로 프로그램이 실행된 시간을 출력한다. 이렇게 측정해본 결과 Tu는 4KB I/O 요청에서 2.7us 정도로 측정이 되었고, 디바이스가 4.1us 정도를 사용했다.
결론적으로 동기적인 모델에서는 CPU를 더 효과적으로 사용한다. 왜냐하면 동기 모델에서 spin-waiting을 하기는 하지만, 그게 CPU가 비동기적인 모델에서 걸리는 시간보다 적기 때문이다.
동기적인 모델에서는 하드웨어 성능이 좋아지면 바로 소프트웨어적 스택의 오버헤드도 개선된다. 하지만 비동기 모델에서는 그렇지 않다. 예를 들어 PCIe Gen3 버스에서는 spin-wait을 하는 시간이 2.9us에서 1.5us로 줄어들었지만, 비동기 모델의 오버헤드는 그대로 6.3us였다. 물론 반대로 SSD가 느려지면 동기 모델에서 바로 성능이 나빠지는 반면 비동기 모델에서는 큰 차이가 없다.
Further issues with interrupt-driven I/O
동기 모델은 지연 시간의 감소 뿐만 아니라 같은 시간 내의 더 많은 IOPS를 처리할 수 있도록 한다. 그림 3에서는 512B I/O 요청을 처리할 때, CPU가 늘어남에 따라 IOPS가 얼마나 증가하는지를 보여준다. 이 테스트에서는 두 모델 모두 CPU의 100%를 사용한다. 동기 모델은 CPU마다 스레드를 하나씩 돌리고, 비동기 모델은 CPU별로 최대 8개의 스레드를 돌린다.
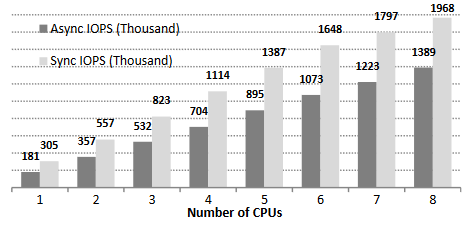
동기 모델은 CPU 수가 증가함에 따라 선형적으로 IOPS가 시스템 전체에서 2M IOPS까지 증가한다. 이 2M IOPS는 프로토타입 하드웨어 ㅡ DRAM의 성능이다. 하지만 비동기 모델은 동기 모델의 60~70% 정도의 성능밖에 내지 못한다. 그림3은 비동기 모델이 지연 시간이 매우 낮은 스토리지 디바이스에서 효율적으로 동작하지 않는다는 것을 보여준다.
이러한 비효율성을 다음 섹션에서 논의한다. 하지만 앞으로 할 논의가 지연 시간이 매우 낮은 스토리지 디바이스에서만 적용되는 이야기임을 주의하자. 지연 시간이 높은 스토리지 디바이스에서는 비동기 모델이 더 효율적이다.
Interrupt overhead
비동기 모델은 인터럽트를 발생한다. 그리고 인터럽트는 부가적이고 불필요한 오버헤드를 만들어낸다. 또 다른 문제는 커널이 인터럽트를 높은 우선순위로 처리한다는 점이다. 우리의 프로토타입 디바이스는 초당 수십만개의 인터럽트를 발생시킬 수 있다. 비동기 모델이 하드웨어 인터럽트 한 번에 여러 개의 I/O 요청을 처리하긴 하지만, 인터럽트의 수가 너무 많아서 시스템을 포화시킨다. 인터럽트 여러 개를 한 번에 처리하면 오버헤드와 지연 시간을 줄일 수 있다
Cache and TLB pollution
짧은 I/O 대기 시간은 비효율적으로 다른 프로세스를 스케줄링하게 하기도 하지만, 하드웨어 캐시와 TLB를 오염시킨다. 왜냐하면 스케줄러가 I/O를 처리하는 동안 최대한 다른 프로세스를 실행하려고 하기 때문이다. 하지만 우리의 프로토타입 하드웨어에서는 다른 프로세스가 사용할 수 있는 시간이 2.7us뿐이다. 2.7us는 8000 CPU 사이클 정도이다. I/O를 처리하는 동안 스케줄링된 스레드가 I/O를 요청한 스레드보다 더 낮은 우선순위를 갖고 있으면 I/O 처리가 끝난 후 원래의 스레드를 다시 스케줄링한다. ㅡ 매우 비효율적으로 컨텍스트 스위칭이 발생한다. 게다가 컨텍스트 스위칭을 하면 하드웨어 캐시와 TLB가 변경되기 때문에, 원래 스레드로 돌아왔을 때 다시 캐시로 데이터를 불러와야 한다.
CPU power-state complications
비동기 모델에서의 전원 관리는 전원을 제대로 절약하지 못할 뿐만 아니라 I/O 지연 시간도 높인다. 현대적인 프로세서는 사용률이 낮거나 없을 때 전원을 절약하는 'C-state'로 전환된다. C-state로 전환되는 것도 지연 시간을 발생시킨다. 비동기 모델에서는 I/O 요청을 보낸 후에 스케줄링을 할 스레드가 없으면 C-state로 전환되기 때문에 지연 시간이 생긴다. 동기 모델은 I/O를 처리하는 동안에도 프로세서가 바쁘기 때문에 C-state로 전환하지 않는다.
이 논문에서는 C-state 전환으로 인한 지연 시간도 측정했다. 만약 I/O 처리 중에 프로세서가 C-state로 전환하면 2us가 추가적으로 지연된다. 이 지연 시간은 프로세서에 I/O를 처리하는 스레드만 존재할 때 발생한다. 결과적으로 CPU에서 하나의 스레드만 돌아갈 때 비동기 모델은 더 느려진다.
하지만 비동기 모델에서 C-state 전환을 조절하기도 쉽지 않다. 비동기 모델에서는 C-state로의 전환이 스케줄러나 CPU에 의해 결정되기 때문에 블록 I/O 서브시스템에서 이를 제어하기가 어렵다. 반면에 동기 모델은 spin-wait 루프를 돌기 때문에 C-state로 전환하지 않는다.
Correctness of synchronouns model
블록 I/O 서브시스템은 클라이언트가 요청한 I/O 요청의 순서를 바꿀 때 클라이언트가 요청한 순서대로 올바른 것으로 간주된다. 궁극적으로 우리는 하나의 문제를 강조하고 싶다.
클라이언트가 요청 A와 B를 순서대로 요청했을 때 B보다 A가 먼저 처리되어야 한다면, 동기 모델은 이 요구사항을 만족할 수 있는가?
명료함을 위해 클라이언트는 리눅스 I/O 시스템 호출을 사용하는 어플리케이션이라고 가정하자. 또한 파일 시스템과 페이지 캐시는 없다고 가정하자. 실제로는 파일 시스템과 페이지 캐시는 그 자체로 블록 I/O 서브시스템을 사용하는 클라이언트로 간주된다.
우선 두 개의 가정부터 시작하자.
- A1: 어플리케이션은 Blocking I/O 시스템 호출을 사용한다.
- A2: 어플리케이션은 싱글 스레드이다.
싱글 스레드가 A와 B를 순서대로 요청한다고 해보자. 운영체제는 그동안 해당 스레드를 다른 CPU에서 실행할 수 있다. 하지만 이렇게 선점 후 스케줄링이 되어도 하나의 스레드만 돌아가기 때문에 A와 B의 순서에는 영향을 미치지 않는다.
이제 A1을 좀더 완화해서 어플리케이션이 Non-blocking I/O이나 AIO (비동기 I/O) 인터페이스를 사용한다고 해보자 [4]. 동기 모델에서는 디바이스가 B를 처리하고 있을 때는 이미 A를 완료했다는 것을 의미하므로 문제가 없다.
다음으로는 A2를 완화해서 T1과 T2라는 두 스레드가 각각 A와 B를 요청한다고 해보자. 그럼 A와 B의 순서를 보장하려면 T1과 T2는 동기화 매커니즘을 사용해야 한다. 그럼 똑같이 B를 요청하는 시점에 이미 A는 완료되어야 한다. 따라서 동기 모델은 Blocking I/O, Non-Blocking I/O, 싱글 스레드, 멀티 스레드 모두에서 순서를 보장할 수 있다.
위의 예제에서는 I/O의 순서 보장을 할때 메모리 배리어가 불필요하다는 것을 보여준다. 반면에 비동기 모델에서는 순서를 보장하기 위해선 메모리 배리어를 사용해야 한다. 따라서 동기 모델은 I/O 루틴을 더 단순화한다.
우리는 리눅스에서 동기 모델을 사용하는 드라이버를 멀티스레드, Non-blocking I/O를 사용하는 어플리케이션에서 테스트했고 스왑 공간을 많이 사용할 때도 문제가 없었다. 우리는 동기 모델이 올바르고 기존의 어플리케이션과도 모두 호환된다고 믿는다.
Discussion
비동기 모델은 더 큰 I/O 요청이나 지연 시간을 발생시키는 hardware stall을 처리하는 데에서 더 잘동할 것이다. 따라서 동기 모델과 비동기 모델은 둘중 하나만 사용하는 게 아니라 필요에 따라서 전환하는 하이브리드 방식으로 사용하는 게 선호될 것이다. 동기 모델은 작고 자주 발생하는 I/O 요청에서 빠르게 동작한다.
우리는 기존의 어플리케이션들이 비동기 모델과 느린 스토리지 디바이스를 가정해서 작성되었을 것이라고 믿는다. 동기 모델이 제대로 작동하려면 기존의 소프트웨어를 조금 수정해야 하지만, 운영체제와 어플리케이션을 조금 수정하면 더 빠르게 동기 모델에서 동작할 것이다. 우리는 어플리케이션을 재작성하지는 않았지만 재작성 하는것을 제안한다.
아마도 동기 모델에서 최대의 성능 개선을 얻는 방법은 동기적인 I/O에서 AIO같은 Non-blocking I/O의 사용을 줄이는 것이지 싶다. 이러한 Non-blocking I/O는 ㅡ Non-blocking I/O 요청 함수가 끝나는 순간 이미 I/O 요청이 완료되어있기 때문에 어플리케이션의 불필요한 오버헤드와 복잡성을 더한다. Non-blocking I/O 인터페이스를 사용하더라도 동기 모델에서 올바르게 작동하지만, 동기 모델을 완전히 활용하지는 못한다.
스토리지 디바이스가 I/O를 동기적으로 수행할 정도로 빠르면, 어플리케이션 내부의 I/O 버퍼를 사용해도 될지 다시 생각해봐야한다. 많은 I/O 집약적인 어플리케이션(데이터베이스, 페이지 캐시, 디스크 스왑 알고리즘 같은)이 I/O 버퍼링과 prefetching을 사용한다. 이렇게 어플리케이션 단에서 I/O에 대한 최적화를 하는 것은 동기 모델을 사용할 때 별다른 효과 없이 오버헤드만 추가하게 될 수도 있다.
동기 모델이 I/O 처리의 오버헤드를 단순화하지만 어플리케이션이 병목이 될 수 있다. 예를 들어 I/O prefetching은 별로 효과적이지 못하고 오히려 독이 될 수도 있다. 우리는 페이지 캐시의 read-ahead와 swap-in clustering을 비활성화했을 때 페이지 캐시와 disk-swapper의 성능이 올라가는 것을 발견했다.
따라서 어플리케이션이 동기 모델에 대해서 알고있어야한다. 예를 들어 ioctl()로 동기 모델을 사용하는 것이 좋을지 질의를 날려볼 수도 있다. 그리고 운영체제는 spinning I/O wait 루프에서 얼마나 사이클을 사용하는지 측정하는 방법을 제공해야 한다. 현재로서는 측정할 방법이 없다. 우리의 프로토타입 구현에서는 시스템 시간으로 폴링 루프에서 보낸 시간을 측정할 수 있었지만, 다른 사람들은 시스템 시간 때문에 I/O가 처리되지 않았거나 커널의 비효율성을 의심할 수도 있다.
Related work
NAND 기반의 스토리지가 발전하면서 차세대 Non-Volatile Memory에 대한 연구가 급등했다 [11,14,16,19]. 기본 구성은 다르지만 차세대 스토리지가 개발되면 지금의 NAND 기반 스토리지보다 더 빠르고 간단해질 것이다.
차세대 NVM 기술의 DRAM에 가까운 랜덤 접근 성능 덕분에 NVM이 직접적으로 물리 주소 공간에 노출되는 storage-class memory (SCM)에 대한 연구도 활발하다. 예를 들어 SCM 기반 구조의 파일시스템도 제안되고 있다 [9,21]. 반대로 우리는 차세대 NVM을 더 발전적으로 접근한다. 기존에 존재하는 어플리케이션을 거의 그대로 유지하기 때문이다.
Moneta [8]는 차세대 NVM 기반 SSD를 재평가하려는 최근의 시도이다. Moneta 하드웨어는 PCIe 버스에 연결된 블록 디바이스라는 점에서 우리의 프로토타입 디바이스를 닮았다. 하지만 구현의 차이로 인해 우리의 하드웨어가 더 빠르게 동작한다. 그리고 Moneta는 spinning하는 비용을 측정한다. 하지만 이 비용을 지연 시간 관점에서만 설명한다. 하지만 이 논문은 동기 모델의 실현 가능성과 IOPS 확장성, interrupt thrasing, power state 등 다양한 관점에서 설명한다.
인터럽트 기반 비동기 모델은 오랫동안 유일한 I/O 모델이었다. 따라서 스토리지 인터페이스 표준은 하드웨어 큐 기술을 사용해서 비동기 I/O 연산의 성능을 개선했다 (인터럽트 병합을 말하는 것 같다.)[2,5,6]. 하지만 이런 방법은 하드 디스크나 NAND 플래시에서 효과적이고 매우 낮은 지연 시간의 SSD에서는 효과적이지 않다.
대기 시간이 짧을 때 이벤트 기반이 아니라 폴링을 사용하는 것은 잘 알려진 전략이다. 예를 들어 스핀락은 락을 들고있는 시간이 짧을 때 뮤텍스보다 많이 사용한다. 다른 예제로는 고성능 컴퓨팅 클러스터에서 MPI 라이브러리를 사용해서 네트워크 메시지 패싱을 할 때도 폴링이 사용된다. 이런 시스템에서는 RDMA와 같은 고성능 네트워크 스택으로 인해서 몇 us 정도밖에 지연 시간이 발생하지 않는다.
Conclusion
이 논문에서는 I/O 요청을 동기적으로 처리하는 모델을 설명했다. 차세대 NVM 기술을 사용하는 매우 지연 시간이 낮은 디바이스에서는 인터럽트 기반 방식보다 폴링이 더 효율적으로 작동한다는 것을 알아보았다. 우리의 결론은 커널 연구자들이 차세대 NVM 기술을 생각해서 미래의 SSD에서의 최적화를 고려해야한다는 것이다. 우리는 그렇게 많은 것을 바꾸지 않아도 의미있는 성능 개선이 가능하다고 생각한다.
References
[1] Jen Axboe. Flexible I/O tester (fio). http://git.kernel.dk/?p=fio.git;a=summary. 2010.
[2] Amber Huffman and Joni Clark. Serial ATA native command queueing. Technical white paper,
http://www.seagate.com/content/pdf/whitepaper/D2c_tech_paper_intc-stx_sata_ncq.pdf, July 2003.
[3] Intel Corporation. Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 1-3. Intel, 2008.
[4] M. Tim Jones. Boost application performance using asynchronous I/O. http://www.ibm.com/developerworks/linux/library/l-async/, 2006.
[5] NVMHCI Work Group. NVM Express. http://www.nvmexpress.org/, 2011.
[6] SCSI Tagged Command Queueing, SCSI Architecture Model – 3, 2007.
[7] Daniel P. Bovet and Marco Cesati. Understanding the Linux Kernel, 3rd Ed., O’Reilly, 2005.
[8] Adrian M. Caufield, Arup De, Joel Coburn, Todor I. Mollov, Rajesh K. Gupta, and Steven Swanson. Moneta: A high-performance storage array architecture for next-generation, non-volatile memories, In Proceedings of the 43rd International Symposium of Microarchitecture (MICRO), Atlanta, GA, December 2010.
[9] Jeremy Condit, Edmund B. Nightingale, Christopher Frost, Engin Ipek, Benjamin Lee, Doug Burger, and Derrick Coetzee. Better I/O through byte-addressable, persistent memory. In Proceedings of the Symposium
on Operating Systems Principles (SOSP), pages 133–146, Big Sky, MT, October 2009.
[10] Jonathan Corbet, Alessandro Rubini, and Greg Kroah-Hartman. Linux Device Drivers, 3rd Ed., O’Reilly, 2005.
[11] B. Dieny, R. Sousa, G. Prenat, and U. Ebels, Spin-dependent phenomena and their implementation in spintronic devices. In International Symposium on VLSI Technology, Systems and Applications (VLSI-TSA), 2008.
[12] Annie Foong, Bryan Veal, and Frank Hady. Towards SSD-ready enterprise platforms. In Proceedings of the 1st International Workshop on Accelerating Data Management Systems Using Modern Processor and Storage Architectures (ADMS), Singapore, September 2010.
[13] William Gropp, Ewing Lusk, Nathan Doss and Anthony Skjellum. A high-performance, portable implementation of the MPI message passing interface standard. Parallel Computing, 22:789-828, September 1996.
[14] S. Parkin. Racetrack memory: A storage class memory based on current controlled magnetic domain wall motion. In Device Research Conference (DRC), pages 3-6, 2009.
[15] Moinuddin K. Qureshi, Vijayalakshmi Srinivasan, and Jude A. Rivers. Scalable high performance main memory system using Ph ase-Change Memory technology. In Proceedings of the 36th International Symposium of Computer Architecture (ISCA), Austin, TX, June 2009.
[16] S. Raoux, G. W. Burr, M. J. Breitwisch, C. T. Rettner, Y.-C. Chen, R. M. Shelby, M. Salinga, D. Krebs, S.-H. Chen, H.-L. Lung, and C. H. Lam. Ph ase-change random access memory: A scalable technology. IBM Journal of Research and Development, 52:465-480, 2008.
[17] Dongjun Shin. SSD. In Linux Storage and Filesystem Workshop, San Jose, CA, February 2008.
[18] David Sitsky and Kenichi Hayashi. An MPI library which uses polling, interrupts and remote copying for the Fujitsu AP1000+. In Proceedings of the 2nd International Symposium on Parallel Architectures, Algorithms, and Networks (ISPAN), Beijing, China, June 1996.
[19] D. B. Strukov, G. S. Snider, D. R. Stewart, and R. S. Williams. The missing memristor found. Nature, 453(7191):80-83, May 2008.
[20] Sayantan Sur, Hyun-Wook Jin, Lei Chai, and Dhabaleswar K. Panda. RDMA read based rendezvous protocol for MPI over InfiniBand: design alternatives and benefits. In Proceedings of the 11th Symposium on Principles and Practice of Parallel Programming (PPoPP), pages 32-39, New York, NY, March 2006.
[21] Xiaojian Wu and Narasimha Reddy. SCMFS: A file system for storage class memory. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC11), Seat-
tle, WA, November 2011.
'Kernel' 카테고리의 다른 글
| Direct Memory Access API (0) | 2021.12.29 |
|---|---|
| [Linux Kernel] 리눅스는 얼마나 작아질 수 있을까? (0) | 2021.12.05 |
| [Linux Kernel] 부팅 초기에 Abort가 나서 로그가 안보일때 (0) | 2021.10.16 |
| 리눅스와 오픈소스에 관한 생각 (3) | 2021.09.23 |
| [LWN.net] More IOPS with BIO Caching (0) | 2021.09.19 |




댓글