Paging Overview
운영체제를 배울때 우리는 페이징이 가상 주소를 물리 주소로 변환하는 매커니즘이고 다단계 페이지 테이블을 사용해서 어떤 가상주소를 어떤 물리주소로 매핑할지 정할 수 있다고 배웠다. 요즘엔 일반적으로 3, 4, 5단계 페이지 테이블을 사용한다. 다단계 페이지 테이블을 사용하는 이유는 fork()할 때 페이지 테이블을 복사하는 비용을 줄이기 위함이고, 페이지 테이블의 단계가 많아질수록 page table walking 비용이 늘어나는 대신 사용할 수 있는 주소의 범위가 늘어난다.
그럼 CPU가 메모리 접근을 할때마다 page table walking을 해야하는가? 그렇지는 않다. 가상 주소를 물리 주소로 변환하려면 적어도 페이지 테이블 단계 수만큼은 메모리 접근을 해야하므로 CPU 입장에서 page table walking은 매우 비싼 작업이다. (수백 나노초 정도 걸린다.) 그렇기 때문에 CPU 내부에는 TLB (Translation Lookaside Buffer)라는 캐시가 존재하고 (일반적으로 Set-Associative Mapping방식의 캐시로 구현된다.) 캐시에 주소 변환의 결과가 저장된 경우에는 캐시에서 결과를 가져와서 빠르고, 캐시에 없다면 page table walking을 한 뒤에 캐시에 결과를 저장한다.
보통 TLB의 크기는 그렇게 여유롭지 않다. 최근 나오는 CPU들을 보면 L1 TLB 크기가 수십개의 엔트리, L2 TLB의 크기가 수백/수천개 정도다. 그리고 커널 스레드 간에는 주소 공간이 모두 같지만 (물론 최근에는 커널 스레드 사이에도 주소 공간을 분리하려는 움직임이 있다.), 사용자 프로세스간에는 주소 공간이 다르므로 context switching을 할때마다 TLB와 캐시 모두 flush를 해야한다. 최근에는 KPTI를 사용하게 되면서 프로세스간 context switching 뿐만 아니라 사용자 모드와 커널 모드를 왔다갔다 하는 데에도 TLB flushing을 하게 되었다.
또한 page table walking은 운영체제가 아닌 CPU에서 수행하며, 만약 현재 접근하려는 페이지가 메모리 상에 존재하지 않을 경우에는 page fault가 발생해서 운영체제가 이를 처리한다.
아키텍처에 따라 다르지만 일반적으로 페이지 하나의 크기는 4K이다. 아키텍처에 따라서 16K, 64K, 1M 등 다양한 크기를 지원할 수 있다. 페이징을 지원하는 모든 아키텍처는 페이지별로 어떤 물리주소로 매핑할지 정할 수 있다. 만약 페이지가 4K이고 메모리가 4G라면 2^18개의 매핑이 필요하다.
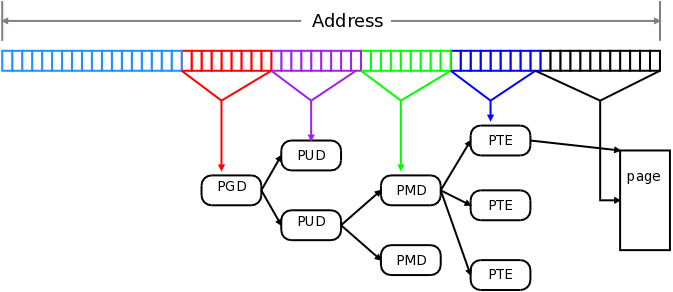
Huge Mapping
일부 아키텍처는 페이지 하나보다 더 큰 단위로 매핑해서, 더 적은 TLB 엔트리를 사용할 수 있다. (그럼 당연히 TLB miss도 줄어든다.) 예를 들어서 x86 아키텍처에서는 PMD 엔트리 하나(512 PTE = 2M), PUD 엔트리 하나 (512 PMD = 1G)정도의 큰 단위로 가상 주소와 물리 주소를 매핑할 수 있다.
그래서 일반적으로 커다란 매핑을 지원하는 아키텍처는 부팅 초기에 페이지 테이블을 초기화할 때 2M, 1G 등의 큰 단위로 매핑한다. (물론 2M, 1G 크기로 주소가 정렬되어있어야 함.) 그래서 커널 스레드는 일반적으로 사용자 프로세스보다 TLB miss가 덜 발생하게 된다.
사용자 프로세스의 페이지 테이블에서도 큰 단위의 매핑을 활용하려면 메모리 자체를 2M, 1G 단위로 할당해야 한다. 근데 text, data, stack, heap 등등 영역별로 각각 할당해야 하므로 내부 단편화가 많이 생길 것이다. 그래서 THP는 무작정 huge page를 할당하는게 아니라 다양한 작동 방식을 지원한다.
/sys/kernel/mm/transparent_hugepage/enabled
이 파라미터는 THP를 어떤 방식으로 작동하게 할지 정한다.
always
madvise()로 MADV_NOHUGEPAGE를 명시하지 않은 모든 프로세스가 THP를 사용하도록 한다.
madvise
madvise()로 MADV_HUGEPAGE를 명시한 프로세스만 page fault시 THP를 사용하도록 한다. khugepaged도 madvise()로 명시한 VMA만 collapse한다.
never
THP를 완전히 비활성화한다.
Allocate Huge Page on Page Fault
THP의 enabled 값에 따라서 커널은 page fault가 발생할 때 huge page를 할당해서 사용한다. 이때 사용 가능한 huge page가 없는 경우에는 direct relcaimation이나 direct compaction을 수행해서 huge page를 만들어야 하는데. 이런 direct reclaimation/compaction은 page fault의 latency를 크게 증가시킬 수 있기 때문에 /sys/kernel/mm/transparent_hugepage/defrag 파라미터로 얼마나 열심히 defragmentation을 할 것인지 명시할 수 있다.
Splitting Huge Pages
THP 이전에 사용하던 hugetlbfs는 huge page를 그냥 잠궈버려서 커널의 다른 서브시스템이 건드리지 못하도록 했다. 그래서 스왑이 불가능했다. THP를 만든 Andrea Arcangeli는 이 점을 감안해서 필요에 따라서 THP를 더 작은 페이지들로 나눌 수 있도록 했다.
Collapsing Small Pages to Huge Pages
Page Fault에서 huge page를 할당했는데 이후에 swap등의 이유로 다시 split되었다면 TLB miss는 다시 증가한다. 이런 경우를 위해 커널에서 khugepaged라는 스레드가 vma들을 스캔하며 huge page를 사용할 수 있는 경우에는 작은 페이지들을 huge page로 합친다. 그렇다고 무작정 합치는 것은 아니고, 512개의 PTE중 256개 이상이 자주 접근된다면 하나의 PMD로 합치는 식이다. collapse를 할 때는 huge page에 작은 페이지들을 모두 복사한 후 페이지 테이블을 수정해야하는 오버헤드가 있다.
/sys/kernel/mm/transparent_hugepage/defrag (defragmentation control)
이 파라미터는 사용 가능한 huge page가 존재하지 않을 때 얼마나 열심히 defragmentation을 수행할지를 의미한다.
always
page fault를 할때마다 항상 direct reclaimation과 direct compaction을 수행한다.
deferred
프로세스가 kswapd/kcompactd를 깨워서 백그라운드에서 reclaimation/compaction이 수행되도록 한다. huge page를 page fault시에는 사용하지 않고 khugepaged를 사용해서 collapse한다.
deferred+madvise
madvise로 MADV_HUGEPAGE를 명시한 프로세스들은 page fault시에 direct reclamation/compaction을 수행하고, 그렇지않은 프로세스들은 kswapd/kcompactd를 깨운다.
madvise (기본값)
madvise()로 MADV_HUGEPAGE를 명시한 프로세스만 direct reclaimation/compaction을 수행한다.
never
defragmentation을 수행하지 않는다.
Disadvantages
THP는 TLB miss의 감소라는 장점이 명확하지만 단점도 존재한다. 우선 시간이 지남에 따라서 high-order page들을 구하기가 어려워진다는 점과, huge page가 없을 경우 해야하는 reclamation과 compaction이 비싼 작업이라는 점, compaction이 parallel하게 이루어지기 어렵다는 점 등이다. [link]
Anonymous Pages & Read-Only File-backed Pages
현재로서 THP는 anonymous page를 주로 지원하고, file-backed page같은 경우에는 파일시스템을 수정해야할 부분이 많아서 read-only로 열린 파일에 대해서만 지원한다.
Recent Works
THP 관련된 최근 작업들로는 khugepaged가 아닌 사용자 프로세스가 직접 ROTHP collapsing을 할 수 있도록 하는 패치 [mail], ROTHP를 khugepaged가 VMA를 스캔하다가 우연히 collapse하는게 아니라 khugepaged에 좀더 명시적으로 알려주도록 하는 패치[mail]가 있다. 둘다 아직 리뷰 단계이다.
DAMON기반 huge page collapse/split [mail]. DAMON은 v5.15에 머지된 모듈로 랜덤하게 page table을 스캔해서 워킹 셋을 측정하는 모듈인데 huge page 말고도 proactive reclamation/compaction, tiered memory promotion, LRU (de)activation 등등 다양한 용도로 사용할 계획인 것 같다. 아직은 아이디어 단계인듯.
Read Only THP support for FS [mail], [lwn], [commit]
proactive memory compaction. [lwn] [commit] 이건 THP 코드와 직접적으로는 상관없지만 사용 가능한 high-order page가 많을수록 direct compaction/reclamation을 하지 않아도 되므로 도움이 된다.
Transparent Hugepage Support — The Linux Kernel documentation
This document describes design principles for Transparent Hugepage (THP) support and its interaction with other parts of the memory management system. get_user_pages and follow_page get_user_pages and follow_page if run on a hugepage, will return the head
www.kernel.org
Transparent hugepages [LWN.net]
This article brought to you by LWN subscribersSubscribers to LWN.net made this article — and everything that surrounds it — possible. If you appreciate our content, please buy a subscription and make the next set of articles possible. By Jonathan Corbe
lwn.net
Transparent Hugepage Support — The Linux Kernel documentation
Khugepaged controls khugepaged runs usually at low frequency so while one may not want to invoke defrag algorithms synchronously during the page faults, it should be worth invoking defrag at least in khugepaged. However it’s also possible to disable defr
www.kernel.org
'Kernel > Memory Management' 카테고리의 다른 글
| KFENCE: Kernel Electric-Fence (2) | 2022.04.17 |
|---|---|
| KASAN: Kernel Address SANitizer (0) | 2022.04.09 |
| Virtual Memory: Memory Compaction (0) | 2022.01.10 |
| Virtual Memory: Zone의 종류 (0) | 2022.01.03 |
| Virtual Memory: Grouping pages by mobility (0) | 2022.01.02 |




댓글