
이 글은 한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.
동시성 프로그래밍
Rust 언어를 중심으로 어셈블리어, C 언어를 사용해 CPU 아토믹 처리, 소프트웨어 트랜잭셔널 메모리, async/await 등 동시성 프로그래밍과 관련된 이론적 배경부터 구현까지 설계자 입장에서 살펴본
hanbit.co.kr
개요
2000년대에 들어서면서 그 유명한 무어의 법칙이 깨지고 프로세서의 clock rate 향상에 한계가 생기면서 multi-core/many-core 프로세서가 트렌드로 접어든지 오래이다. 프로세서가 하나라고 가정하고 짠 프로그램은 더 많아진 프로세서를 제대로 활용하지 못하기 때문에, 이제는 많은 개발자들이 병렬 프로그래밍에 대해서 잘 알아야한다.
이 책은 동시성 프로그래밍의 개념을 전체적으로 잡고, 관련된 여러 가지 개념을 찍먹하는 데에 좋다. 다만 동시성 프로그래밍은 컴퓨터 구조에 대한 지식을 많이 요구하기 때문에 컴퓨터 구조와 같이 공부하면 더 좋을 것 같다. 책의 내용을 간략하게 정리해봤는데, 읽어보고 흥미가 생긴다면 일독을 권한다.
동시성 vs 병렬성
동시성(Concurrency)이란 2개 이상의 프로세스가 계산 중인 상태에 놓이는 것을 말한다. "동시에 두 프로세스가 계산을 한다"와 "동시에 두 프로세스가 계산을 하는 상태에 놓이는 것"은 의미가 다름에 유의하자. 리눅스로 치면 2개 이상의 프로세스가 TASK_RUNNING 상태에 놓인다면 동시성을 띈다고 할 수 있다.
반면 프로세스 관점에서의 병렬성은 "동시에 두 개 이상의 프로세스가 계산을 할 수 있음"을 말하며, 이는 적어도 2개 이상의 논리적 프로세서가 있을 때 의미가 있다. 왜냐면 병렬성은 기본적으로 (병렬성으로 인한 오버헤드와 추가적인 문제를 감안해서라도) 문제를 더 빨리 계산하기 위한 것이기 때문이다.
하드웨어 병렬성
그런데 프로세스 관점에서의 병렬성 말고, 하드웨어 관점에서 살펴보면 크게 instruction level parallelism, data parallelism, task parallelism으로 나눌 수 있다.
data parallelism
data parallelism은 일반적으로 하나 이상의 프로세서에서 같은 작업을 수행하되 데이터를 병렬로 처리하는 것을 의미한다. 현대적인 프로세서에서는 SIMD 명령어를 통해서 더 좋은 data parallelism을 실현할 수 있게 해준다. (물론 요즘은 GPU/TPU/NPU가 엄청 좋아졌지만...) data parallelism은 데이터를 분산하는 데에 초점을 둔다.
task (thread) parallelism
반면 task parallelism은 서로 같거나 다른 태스크가 동시에 연산을 수행함을 말한다. 예를 들어 어떤 작업을 여러 단계로 나누어서 pipelining (주의: 프로세서 에서의 파이프라이닝을 말하는 것이 아님!) 하고 동시에 실행하는 것을 예로 들 수 있다. task parallelism은 작업을 여러 프로세서, 컴퓨터에 분산하여 처리하는 데에 중점을 둔다.
instruction level parallelism
instruction level parallelism은 하나의 프로세서가 동시에 여러 개의 instruction을 처리할 수 있음을 의미한다. 그렇게 하기 위해서 현대적인 프로세서들은 instruction pipelining을 여러 개의 pipeline을 갖기도 한다. ILP는 명령어 간의 종속성이 적을 수록 효과가 좋아진다.
Amdahl's Law
병렬화를 하면 작업이 얼마나 더 빨리 끝날까? 이상적인 병렬 어플리케이션은 (프로세서가 한 개일 때 걸린 시간)/(프로세서 수)대로 시간이 단축되겠지만, 현실에서는 그렇지 않다. 모든 작업이 병렬화를 할 수 있지 않을 뿐더러, 병렬화로 인한 오버헤드도 존재하기 때문이다.
Gene Amdahl에 따르면 작업의 일부를 병렬화했을 때 전체 성능이 어떻게 영향을 미치는지는 다음의 식에 따른다.
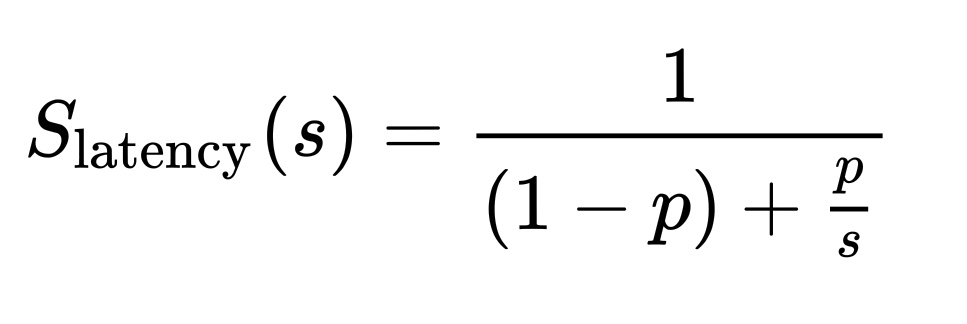
위 식에서 S_latency는 이론적인 성능 향상률, p는 전체 작업에서 병렬화가 가능한 비율이며, s는 병렬화 수를 나타낸다. 만약 여기서 p = 1.0이라면 아주 이상적으로 s가 증가할 수록 latency가 계속 줄어든다. (물론 위 식은 병렬화의 오버헤드를 고려하지 않으며 현실에서는 오버헤드도 고려해야 한다.)
현실은 이상과 괴리가 있기 때문에 대부분 p < 1이며 병렬화를 조금밖에 할 수 없다면 성능 향상도 크지 않다. 여기서 Amdahl이 말하고 싶었던 것은, "전체 작업 중 일부에 대한 성능을 개선했을 때는 일부에 대한 비율만큼만 개선이 이루어진다"인듯 하다.
다양한 종류의 락들
병렬화 할 때는 여러 태스크 간에 자원을 적절히 공유해야 하기 때문에, 락을 사용해서 동기화를 하게 된다. 락을 구현하기 위해서 아키텍처는 Compare and Swap, Load-Link/Store-Conditional 등의 원자적 연산을 지원하며, 운영체제는 이를 기반으로 태스크들이 상호 배타적으로 자원에 접근할 수 있도록 한다.
락은 종류가 다양하며, 상황에 따라서 적절하게 사용한다. 예를 들어서 일반적인 상황에서는 뮤텍스를 많이 사용하지만, 읽기가 많이 발생할 때는 Readers-Writer락이나 RCU를 사용하기도 한다. 또한 같은 뮤텍스라도 경우에 따라서 Test-And-Set, Ticket, MCS 등 다양한 구현체가 존재한다.
동시성 프로그래밍 특유 버그와 문제점
락을 사용하기 때문에 발생하는 문제들이 몇가지 있다. 락과 락 사이의 의존성으로 인해 컴퓨터가 영원히 멈추게되는 데드락이나, 데드락은 아니지만 락을 획득하고 해제하는 것만 반복할 수 있는 라이브락 등이 그렇다. 락을 사용하기 위해서 이러한 문제들을 적절하게 이해하고 피할 필요가 있다.
Transactional Memory & Lock-free algorithm
락을 획득한 동안에는 다른 프로세스가 같은 임계 영역에 절대로 접근할 수 없다. 이와는 다르게 다른 프로세스가 트랜잭션을 시도할 수 있도록 하되, 하나의 트랜잭션만 성공하고 실패한 트랜잭션은 다시 시도하는 transactional memory라는 동시성 제어 방식도 있다. TM은 hardware 기반과 software 기반 두 가지 방식이 존재한다.
원자적 연산과 transactional memory를 이용하면 하나의 프로세스가 터져도(?) 다른 프로세스에 영향을 미치지 않는 Non-blocking algorithm 혹은 lock-free algorithm을 구현할 수 있다. 단, 이때 "중간에 데이터에 변화가 생겼는지" 여부를 대해 잘못 판단을 내리게 되는 ABA problem을 각별히 주의해야 한다.
Asynchoronous Programming
이 책은 Rust에서 정해진 순서대로(synchoronous)가 아닌 이벤트 발생에 따라 비동기(asynchoronous)적으로 작업을 처리할지에 대해서도 설명한다. 비동기적으로 처리한다고 해서 꼭 병렬적이라고 할 수는 없지만, 개발자가 병렬 프로그래밍을 더 쉽게 하도록 도와주지 않나 싶다 (지적 환영).
Further Reading
Computer Organization and Design - 교보문고
The Hardware/Software Interface | The fifth edition of Computer Organization and Design-winner of a 2014 Textbook Excellence Award (Texty) from The Text and Academic Authors Associat...
www.kyobobook.co.kr
Is Parallel Programming Hard, And, If So, What Can You Do About It?
Is Parallel Programming Hard, And, If So, What Can You Do About It? The current version is v2022.09.25a [PDF] (single-column format [PDF], ebook format [PDF], change log). The default double-column format is easiest on both the trees and the eyes in paperb
mirrors.edge.kernel.org
'MISC' 카테고리의 다른 글
| Grafana에서 bpftrace 사용하기 (feat. Performance Co-Pilot) (3) | 2021.11.28 |
|---|---|
| Grafana로 모니터링 시스템 구축하기 (0) | 2021.11.18 |
| 오드로이드 홈서버 구축기 - 운영체제 설치 (Armbian) (0) | 2021.11.18 |
| 오드로이드 홈서버 구축기 - 하드웨어 구성 (3) | 2021.11.16 |
| 루팅 없이 안드로이드에서 Docker 돌리기 (0) | 2020.09.18 |




댓글