내가 SLAB/SLUB을 잘못 이해했는지 Christoph Lameter 아저씨가 발표한 영상을 한 번 보라고 추천해주셨다. 이 글은 SL[AUO]B: Kernel memory allocator design and philosophy를 정리하고 내 의견을 추가로 적은 것이다. PDF는 여기에 있다.


대부분의 커널 개발자는 (당연히도) 슬랩 할당자와 상호작용을 하게 된다. 슬랩 할당자란 무엇인가?!

기본적으로 메모리 할당은 PAGE_SIZE (4K)로 이루어진다. (그리고 느림) 하지만 작은 크기의 메모리에 대해서는 페이지를 쪼개서 sizeof(struct bio), sizeof(struct sg) 등등 작은 단위로 할당할 수 있고 그게 더 빠르다. 대부분의 서브시스템에서 메모리 할당을 해야하므로 슬랩 할당자는 성능에 되게 예민하다. 슬랩 할당자의 성능이 나쁘면 이를 사용하는 다른 서브시스템에도 악영향을 미친다.
다만 내용을 설명하기 전에 용어를 먼저 설명해야 한다. 'slab'은 슬랩 할당자, 또는 슬랩 할당자에서 사용하는 자료구조를 의미한다. 현재 슬랩 할당자의 종류는 세 가지인데, SLAB/SLUB/SLOB 중 하나를 선택할 수 있다. 이때 'slab'이라고 하면 SLAB/SLUB/SLOB을 통틀어서 말하는 것이고, SLAB/SLUB/SLOB이라고 하면 세 가지 할당자 중 하나를 지칭해서 말하는 것이다.
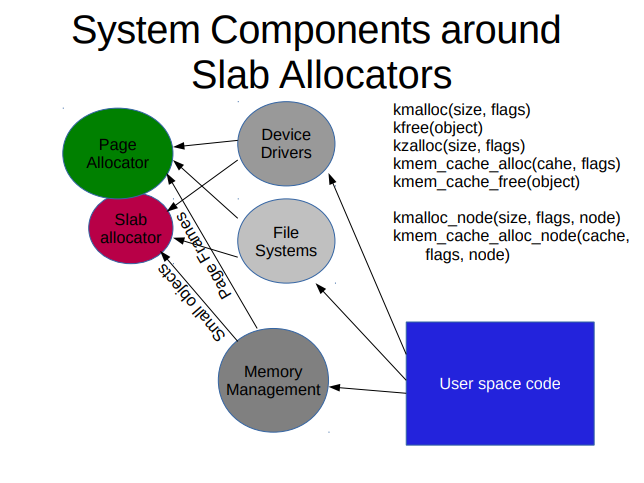
위의 PPT는 여러가지 서브시스템에서 슬랩 할당자, 페이지 할당자의 상호작용을 나타낸다. 서브시스템들은 큰 사이즈의 메모리가 필요한 경우 직접적으로 페이지 할당자에서 메모리를 가져올 수도 있고, 슬랩에서 할당받을 수도 있다. 슬랩은 내부적으로 페이지 할당자 위에서 돌아간다.
사진에는 다양한 인터페이스가 있는데, kmalloc{,_node}, kfree, kzalloc (kmalloc with zeroing)은 더 범용적인 메모리 할당에 사용되고, 특정한 크기의 메모리를 할당한다던가 alignment가 필요하면 kmem_cache를 만들어서 kmem_cache_{alloc,free,alloc_node} 이런 함수들을 써야한다. 슬랩 할당자는 NUMA-aware한 할당자기 때문에 어느 노드에서 메모리를 할당받을지 정할 수 있다.

SLOB (Simple List Of Blocks)은 K&R에서 소개한 아주 심플한 할당자로 메모리가 부족한 환경에서 많이 사용한다. (슬랩이나 슬럽은 할당자 내부에서 사용하는 자료구조로 메모리를 생각보다 많이 먹는다.) SLAB은 Jeff Bonwick의 1994년 논문을 기반으로 작성된 할당자이다. SLUB은 Christoph가 원래 SLAB에서 작업하다가 너무 복잡한 Queueing 때문에 Queueing을 하지 않는 Unqueued allocator인 SLUB을 만들었다.
디자인 철학
- SLOB: 최대한 간결하게
- SLAB: 최대한 cache-friendly하게 (&& benchmark-friendly)
SLAB은 cache hotness를 추적하고자 하고 따라서 2초마다 cache reaper를 돌린다.
Christoph의 의견에 따르면 SLAB의 디버깅 기능은 그렇게 좋지 않다. 디버깅이 잘 안되면 몇기가 바이트의 슬랩 자료구조들을 살펴봐야 하는데 (SLAB은 NUMA 노드가 매우 많을때 MAX_NUMNODES ^ 2 만큼의 alien_cache를 유지하기 때문에 메모리를 상당히 많이 먹는다. 물론 모든 서버가 NUMA 노드가 그정도로 많은 건 아니지만.) 그리고 SLUB이 디버깅 기능이 더 좋다.
- SLUB: 최대한 심플하게 (좋은 디버깅 기능, 실행 시간이 적다, 더 적은 명령으로 실행한다)
SLUB은 현재 커널에서 기본으로 사용하는 할당자이다. 다만 좀 아쉬운 점은 SLUB을 기본 할당자로 설정한 구체적인 이유를 찾을 수 없다.
근데 사실 여기서 잠깐 짚고 넘어가자면 Christoph가 execution time-friendly라고 말하는데 이건 좀 생각해볼 여지가 있다. cache-friendly와 execution-time friendly는 어떻게 다른가? 명령어의 수가 적더라도 cache를 제대로 활용하지 못하면 과연 execution-time friendly라고 할 수 있는 것인가? (물론 SLUB이 더 TLB를 잘 활용하긴 하지만)
하지만 확실한 것은 SLUB은 SLAB보다 간단하고 메모리를 더 적게 사용하며 많은 benchmark 상에서 큰 regression 없이 잘 돌아간다는 점이다. 물론 몇몇 상황에서는 SLAB의 cache-friendliness와 빠른 remote node free로 인해 SLAB이 SLUB보다 더 성능이 잘 나온다.


현재는 여기에 Vlastimil Babka도 포함되어있다.

Nick Piggin은 SLQB를 제안했지만 당시에 Linus가 새로운 슬랩 할당자를 머지하는 것을 더 이상 좋아하지 않아서 머지되지 못했다.
SLOB's data structures

SLOB은 정말 단순하게 free object의 리스트만을 관리하므로 오버헤드가 매우 적고 간결하다. 다만 할당할 때마다 free list를 순회해야하기 때문에 느리고, 메모리의 단편화가 심하다.

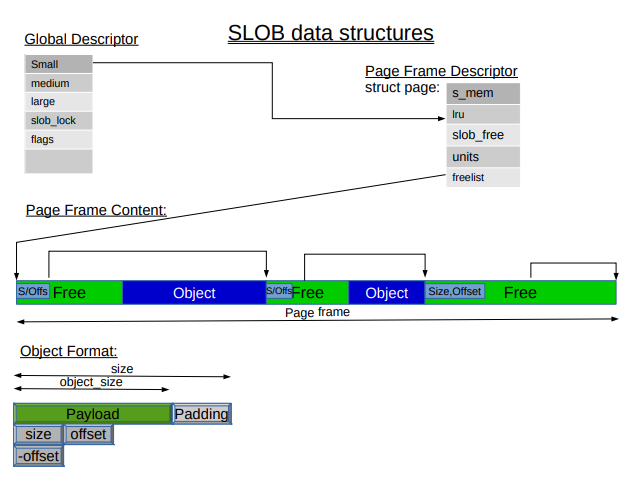
위의 사진은 오브젝트를 사용중인 경우와 아닌 경우로 나눌 수 있다. 오브젝트를 사용중인 경우에는 [Payload][Padding]만 존재하게 되는데, payload는 말 그대로 오브젝트가 저장하고 있는 데이터고, padding은 alignment을 맞추기 위한 미사용 공간이다. 오브젝트를 사용하지 않은 경우 (free된 경우)에는 오브젝트의 사이즈와 다음 free 오브젝트의 오프셋을 나타낸다. 만약 오브젝트가 너무 작으면 size 부분을 사용하지 않고 맨 앞에 offset만 저장한다.

슬랩 할당자는 struct page에 슬랩 페이지에 대한 내용을 기록한다. SLOB은 freelist라는 포인터를 이용해서 struct page상에 해당 페이지의 첫 번째 free object를 가리킨다. SLOB은 free object마다 size와 offset을 사용해서 다음 오브젝트를 가리킬 수 있으므로 freelist를 순회할 수 있다. 위 사진에서 다만 참고할 점은 2013년 즈음에 struct page도 좀 바뀌어서 위의 사진이 좀 안 맞는 부분이 있다. 자세한건 Cramming more into struct page를 참고하자.
SLOB은 오브젝트의 크기가 다 다르기 때문에 (그래서 오브젝트에 사이즈를 기록함) 단편화가 빠르게 발생한다. 그래서 freelist를 크기별로 여러개 만들어서 어느정도 최적화가 되었다.
SLAB's data structures

SLAB은 오브젝트의 cache hotness를 추적하기 위한 queue를 사용한다. 근데 사실 queue라기 보단 스택에 가깝다. (LIFO임) 왜냐하면 가장 마지막에 free한 오브젝트일 수록 더 캐시라인이 살아있을 가능성이 높기 때문이다.
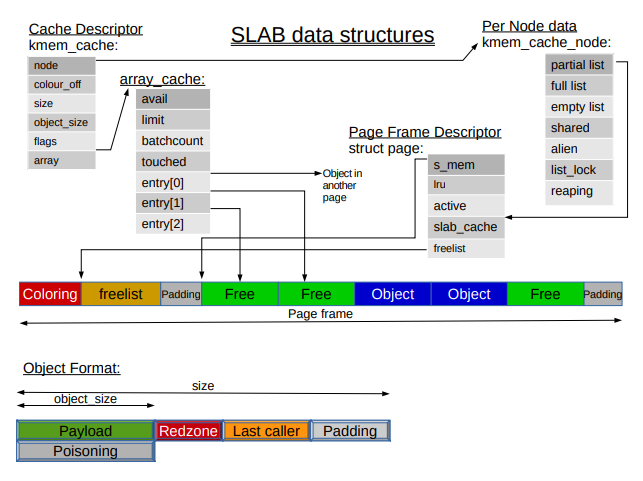
SLAB에서는 per-cpu, per-node queue가 존재한다. 구체적으로는 CPU마다 cpu_cache라는 이름의 queue가 존재하고, node마다 shared queue가 존재한다. 다만 한 가지 단점은 node마다 alien cache라고 하는 remote node의 free를 일괄적으로 하기 위한 queue가 존재해서, 모든 노드에 대해 remote node의 수는 nodes ^ 2이므로 매우 메모리를 비효율적으로 사용한다.
음... 내가 이해 잘못 이해한 것인지 모르겠으나 (아니면 PPT 이후에 코드가 바뀌었을 수도 있다) PPT에도 그렇고 The SLUB allocator에도 그렇고 NR_CPUS * NODES만큼 메모리가 증가한다고 나와있는데 최근에 코드를 분석해본 결과로는 NODES ^ 2만큼의 메모리를 사용한다. 무튼간에 매우 많이 사용한다. 극단적으로 수천개의 프로세서와 수천개의 NUMA 노드가 존재하면 수 기가바이트를 alien cache에 사용한다. 물론 요즘에도 저렇게까지 많은 수의 NUMA 노드가 존재하는 시스템이 흔한지는 잘 모르겠다.
또한 SLAB은 cold object expiration이 존재해서 cache hot하지 않다고 판단되는 오브젝트는 슬랩 캐시로 다시 돌려보낸다. 2초마다 돌려보낸다. 그런데 여기서 또 질문이 생긴다. 물론 alien cache를 비우는 것은 필요하겠지만 cache cold object까지 비우는게 정말로 필요한가? 오히려 queue를 비우는게 더 많은 slowpath를 만들어내지는 않을까? 이건 메일링 리스트에 한번 물어봐야겠다.
그리고 Christoph는 프로세서가 많은 시스템에서 2초마다 queue를 비우는 건 매우 비효율적이고 딜레이가 생긴다고 한다.

SLOB에서는 freelist가 object -> next object -> next object -> ... 이런식으로 순차적으로 이동하는 방식이었지만 SLAB에서는 free object의 인덱스를 배열에 저장해놓는다. 이렇게 하면 freelist의 배열과 실제 free object 2개만 접근하기 때문에 하드웨어 캐시를 더럽히지 않아도 된다. 그리고 슬랩은 캐시 컬러링으로 더 많은 캐시라인을 효율적으로 사용하려고 노력한다. 자세한 건 Jeff Bonwick의 논문을 참조하자.

SLAB에서는 디버깅 용으로 redzone (버퍼 오버플로우 탐지), Last caller (마지막에 누가 호출했는지) 영역을 따로 두고, 오브젝트 안의 데이터를 poisoning하여 free 후에 데이터에 접근했는지를 알아낸다. padding은 위에서 말했듯 alignment를 맞추기 위해 만드는 미사용 공간이다.
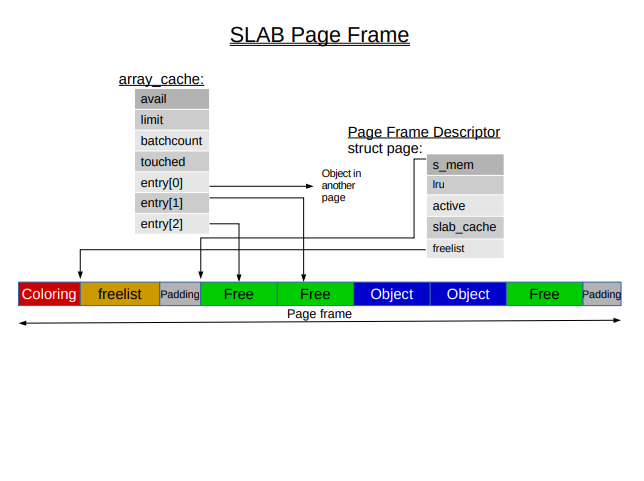
아까 말했듯 SLAB은 per-cpu queue를 갖고 있는데 그게 바로 array_cache 타입의 cpu_cache이다. 이 queue에서는 최근에 free한 오브젝트의 포인터를 갖고있으며 큐 안의 free object pointer들은 서로 다른 슬랩 페이지의 오브젝트를 가리킬 수 있다. 이런 점에서 SLAB은 queueing을 하다가 서로 다른 페이지를 접근하면서 많은 TLB misses를 발생시킬 수 있게 된다.
또한 SLAB은 서로 다른 CPU간에도 shared queue를 사용해서 free 오브젝트를 공유하고자 하는데, 이는 하드웨어 캐시의 계층구조를 활용하기 위함이다. (메모리로부터 캐시에 불러오는 것보단 더 하위 레벨 캐시에서 불러오는 것이 훨씬 빠르다.)
SLUB's data structures

주의: 아래 두 문단은 머릿속에서 살짝 검증을 덜해서 올바르지 않은 정보를 포함할 수도 있다. 링크를 참조해서 조만간 다시 업데이트하겠다.
SLUB은 SLAB에서의 복잡한 queueing을 없앴다. 물론 queue가 아예 존재하지 않는 것은 아니다. 슬랩 페이지 별로 freelist를 queue처럼 사용한다. 다만 SLUB 페이지를 CPU에 연결(? associate를 뭐라고 번역해야하나..)한다. freelist의 오브젝트가 모두 같은 페이지 안에 존재하므로 TLB miss를 줄인다. 결국에 SLUB이 spatial locality가 높다고 하는 것도 이런 이유 때문이다. per cpu partials로 CPU에 하나 이상의 페이지를 연결할 수도 있다.
SLUB은 SLAB과 다르게 cmpxchg_double로 인터럽트를 끄지 않고도 할당하는 fastpath가 존재한다. (물론 이것도 아키텍처에서 cmpxchg_double을 지원하지 않으면 인터럽트를 비활성화 하기는 한다.) 그리고 PPT에 this_cpu_ops와 percpu를 활용한다고 나와있는데 음 이건 무슨얘긴지 아직 잘 몰라서 더 읽어봐야겠다.
SLAB과 SLUB이 memory policy를 기준으로 다른 점은, SLAB은 cache hotness를 추적하느라 오브젝트를 기준으로 queueing을 한다. 따라서 queue의 오브젝트들이 여러 NUMA 노드에 걸쳐서 존재할 수 있다. 하지만 SLUB은 페이지를 기준으로 관리하기 때문에, 불가피하게 다른 노드로부터 메모리를 할당해야 한다면 해당 노드로부터 페이지를 할당받아서 페이지 단위로 관리한다. 따라서 SLAB과 SLUB은 NUMA에서 다르게 작동한다고 할 수 있다.
그리고 SLUB은 SLAB보다 더 단편화가 잘 일어나지 않는다. 음! 이 부분도 제대로 설명을 해주진 않기 때문에 추후 코드를 분석하면서 내용을 덧붙여봐야겠다.
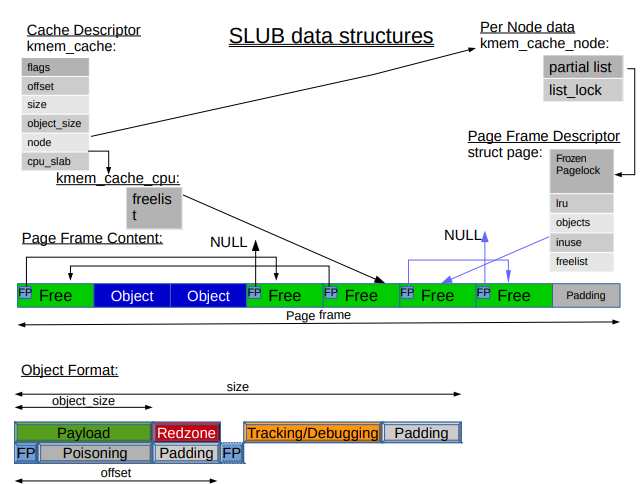
오브젝트의 구조는 SLAB과 비슷하다. 다만 아까 SLAB에서는 'Last Caller'였던 노란색 부분이 여기선 'Tracking/Debugging'이라고 적혀있는데, SLUB은 이 오브젝트가 어느 노드에서 왔는지 등등 더 다양한 정보를 포함한다.
그리고 오브젝트가 free 상태라면 FP (Free Pointer)로 next free object의 payload를 가리킨다. 마찬가지로 Poisoning으로 use after free를 탐지할 수 있다.
그리고 SLUB에서는 두 개의 freelist가 존재하는데, 하나는 페이지 디스크립터의 freelist이다. 이 freelist에 접근할 때는 락을 사용해야 하므로 비용이 더 높다. 두 번째로는 kmem_cache_cpu에도 freelist가 존재하는데, 이 freelist는 특정 슬랩 페이지를 CPU에 연결 (여기선 slab page is dedicated to cpu라고 표현되어있다)했을 때 락 없이 빠르게 접근할 수 있다. 그리고 CPU에서 부터 떨어졌을 때는 다시 페이지 디스크립터에 존재하는 freelist를 사용한다.
다만 여기서 발생할 수 있는 복잡한 상황은, 페이지가 CPU와 연결된 상태에서, 연결되기 이전에 할당된 오브젝트가 다른 CPU나 다른 노드로부터 free되는 경우이다. (페이지가 CPU와 연결되면 할당은 그 CPU에서만 할 수 있다.) 내가 잘 이해한게 맞다면 per-cpu freelist가 텅 비게되었을 때 페이지 디스크립터의 freelist에서 오브젝트를 다시 가져온다는듯 하다.
여기서 궁금한건 왜 사진에서 FP가 두개냐는 것이다. 왜지? 하나가 손실됐을 때 디버깅 용인가?
-> calculate_sizes()를 분석하다보니 FP는 object 내부에 있거나 외부에 있을 때 두 경우로 사용한다. 내부에 있는지 외부에 있는지는 kmem_cache->offset으로 저장한다. 이때 kmem_cache->offset >= kmem_cache->inuse이면 오브젝트 + 레드존의 크기보다 FP의 오프셋이 더 크므로 오브젝트 바깥에 존재한다. 오브젝트 바깥에 두는 경우에는 Poisoning을 하거나, RCU를 쓰거나, 또는 Redzone을 사용하는데 object_size < sizeof(void *)일때 사용한다. 그리고 오브젝트 안에 있을 때도 오브젝트의 처음이 아니라 중간에 배치한다. 중간에 배치하면 몇 바이트 정도만 오버플로우가 났을 때는 FP를 보존할 수 있다.

SLUB이 활성화중일 때는 slabinfo라는 도구로 다양한 디버깅/통계 기능을 사용할 수 있다. 커널 소스 트리의 tools/vm/slabinfo.c를 컴파일하여 사용할 수 있다. 그냥 gcc로 컴파일하면 된다.


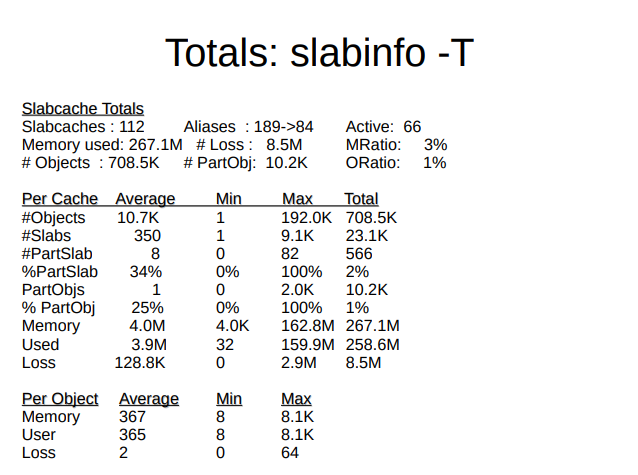
slabinfo -T는 시스템 상에서 슬랩의 전체적인 현황을 보여준다. 한가지 주목할 점은 SLUB에는 Aliasing이라는 기능이 이있어서 성능이 비슷한 캐시들을 합친다. (merge) 따라서 캐시를 더 잘 활용하고 불필요한 오버헤드를 줄이려고 한다. 통계 상에서도 Aliases: 189 -> 84라고 캐시를 얼마나 합쳤는지 보여준다. 흠, slabinfo 툴 관련된 문서도 찾아봐야겠다.

slabinfo -a는 어떻게 aliasing을 했는지 보여준다.

다시 컴파일할 필요 없이 SLUB의 디버깅은 부팅 옵션으로 활성화/비활성화할 수 있다.

Performance comparison
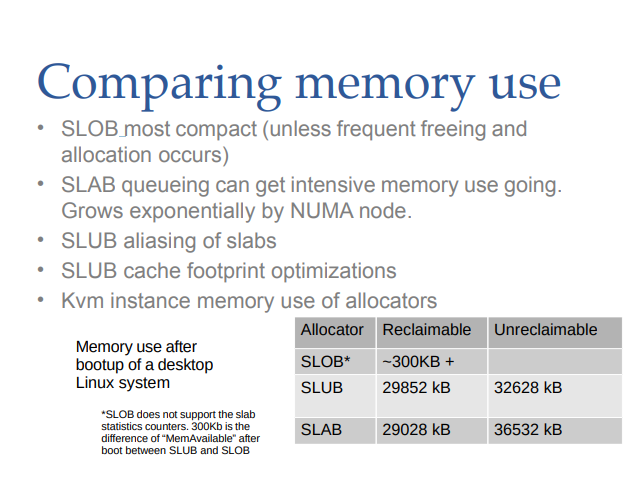
메모리 사용량을 비교해보면, 당연히 SLOB은 메타데이터를 거의 사용하지 않으므로 매우 작은 양의 메모리를 사용한다. SLAB은 queueing 때문에 메모리를 많이 사용하고, SLUB은 queueing을 사용하지 않기도 하고 aliasing을 사용해서 메모리를 더 적게 사용한다. 그리고 SLAB은 SLUB보다 Unreclaimable한 메모리가 더 많은데, 이는 SLAB이 SLUB보다 더 많은 메타데이터를 사용하기 때문이다.

SLOB은 느리고, SLAB은 빠르다. SLUB은 음....... "fast in terms of cycles used for the fastpath"라는 말은 빠르다는 건지 느리다는 건지 솔직히 잘 모르겠다. (하지만 확실히 SLAB보다 더 간단하다.) 하지만 하드웨어 캐시를 잘 활용하지는 못한다. 다만 SLUB은 인터럽트를 비활성화하지 않는 fastpath로 캐싱과 관련된 이슈를 만회하려고 노력한다.
cache footprint는 최근에 들어서 성능에 중요한 영향을 미치는데, benchmark할 때는 대부분의 캐시를 benchmark에 사용하기 때문에 결과가 부적절할 수 있다. 그래서 Christoph는 SLAB이 cache-friendly, benchmark-friendly라고 이야기하는 것 같다.
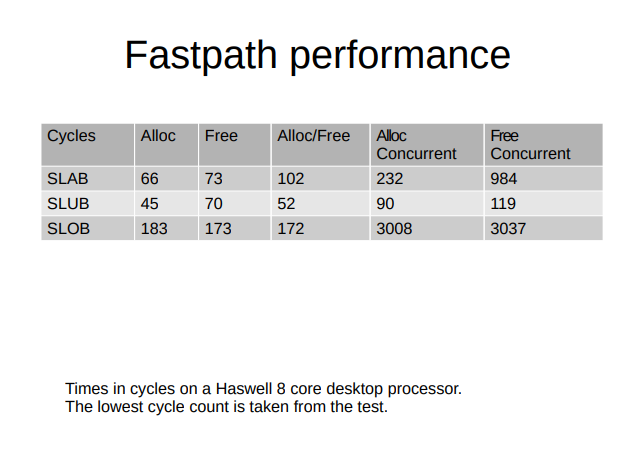
위의 PPT는 fastpath에서 세 할당자가 어느 정도의 cpu cycle를 사용하는지를 보여준다. SLUB이 SLAB보다 더 적은 cpu cycles를 사용한다. execution time friendly, fast in terms of cycles used for the fastpath라는 말이 캐시 때문에 시간은 더 오래 걸리지만 더 적은 cycle을 사용한다는 말인듯? 근데 fastpath가 빠른것과 더 많이 fastpath를 hit하는 것은 또 달라서 좀더 생각해볼 여지가 있다.

hackbench는 SLUB이 좀더 우세하지만 이정도면 SLAB/SLUB이 거의 차이가 없다고 볼 수 있다. 성능 측정 관련해서 요즘 좀 고민인게 슬랩 할당자의 성능을 측정할 척도가 무엇이어야 하는가에 대한 고민이다. allocation speed에 있어선 얼마냐 intensive하게 메모리를 할당하냐가 중요하고, defragmentation도 고려해야 한다. 대부분 예전 메일링 리스트를 보면 hackbench, netperf TCP_RR, kernbench 이런것들을 사용하는듯 하다. 이건 좀더 생각해봐야할듯.

난 이 PPT의 결론이 뭔지 잘 모르겠다. SLUB이 cpu cycle뿐만 아니라 전체적인 성능에서 remote freeing이 SLAB보다 좋았다고 하면 Christoph가 그걸 언급했을텐데 PPT만 딱 있고 'remote freeing은 중요하다'라고만 말한다. 내 생각에는 remote freeing 자체는 SLAB이 더 뛰어난데 cpu cycle은 SLUB이 더 적다는걸 보여주고 싶은 것 같다.

최근(영상이 찍힌 2015 기준) 작업중인 것은 SLAB/SLUB/SLOB의 공통적인 부분을 추상화해서 slab_common으로 만드는 것과, this_cpu 연산으로 SLAB의 fastpath를 작업하는것, SLUB의 fastpath를 작업하는 것이다.
'Move toward per object logic for Defragmentation and maybe to provide an infrastructure for generally movable objects ....' 이 부분은 정확히 무엇을 언급하는지 모르겠다. 공부가 부족하군.
이 글의 TODOs
- bulk alloc API 관련 내용 다루기
- 부족한 부분 더 공부하고 갱신하기 (per-cpu partials, this_cpu ops, per object logic for defragmentation, generally movable objects, FP가 왜 2개인가, 성능 측정은 어떻게 해야하는가)
'Kernel > Slab Allocators' 카테고리의 다른 글
| [Linux Kernel] SLUB 오브젝트 할당/해제 분석 (22) | 2021.10.24 |
|---|---|
| [Linux Kernel] slab_common 분석 (0) | 2021.10.10 |
| The Slab Allocator: An Object-Caching Kernel Memory Allocator (0) | 2021.10.04 |



댓글