코드를 짜다가 캐시를 고려해서 짜야한다는 지적을 받아서 정리해본다.
원문: The Elements of Cache Programming Style (Chris B. Sears, USENIX 2000)
Introduction

캐시 메모리는 당근과 채찍의 원리로 작동한다. 당근은 지역성의 원리(Principle of Locality)이고 채찍은 암달의 법칙이다. 지역성의 원리는 컴퓨터의 메모리 접근이 무작위적이지 않고 규칙이 존재한다는 가정에 근거한다. 이때 시간 지역성 (temporal locality)는 한 번 접근한 메모리는 다시 접근할 확률이 높음을 의미하고, 공간 지역성 (spatial locality)는 접근한 메모리의 주변 메모리에 접근할 확률이 높음을 의미한다.
그리고 암달의 법칙은 더 빠른 구성요소 (여기서는 하드웨어 캐시)의 속도 개선은, 해당 구성요소를 사용하는 시간에 의해 제한된다고 말한다. 이 경우에는 CPU와 캐시가 빠른 구성요소이고 메모리가 느린 구성요소이다.
만약 어떤 프로그램이 지역성의 원리를 준수한다면 캐시 메모리의 이득을 보고 프로세서에 가까운 속도로 실행될 수 있다. 하지만 준수하지 않는다면 메모리의 속도에 가깝게 실행된다. 그리고 눈에 띄게 성능 향상을 보려면 캐시의 hit rate는 매우 높아야한다.
암달의 법칙은 멀티프로세서 환경에서 페널티가 존재한다. 멀티프로세서에서 캐시가 thrashing되거나 동기화를 위해 대기하므로 오히려 멀티프로세서의 이점을 살리지 못하고 역효과가 날 수 있다. 멀티프로세서 환경에서 False Sharing을 피하면서 지역성의 원리를 준수하는 것은 필수적이다.
캐시 프로그래밍 스타일의 목적은 이 지역성을 높이는 것이다. 그러려면 캐시의 구조와 특성을 이해해야 한다. 하지만 캐시를 활용하는 것보다 캐시를 잘못 사용하는 걸 피하는게 더 중요하다. 이 글은 캐시에 대해 자세히 알아보고 가이드라인을 제공한다.
An Example
이 글에서는 리눅스의 스케줄러로 예를 들어서, 코드와 자료구조를 조금 바꿔서 캐시를 더 효율적으로 사용하도록 바꾼다. 그리고 여기서는 1998 350MHz Deschutes Pentium II 시스템을 예로 들어 설명한다. 이 프로세서의 성능은 다음과 같다.

구체적인 성능 수치는 시간이 지나면서 바뀐다. CPU 성능은 약 연간 55%씩 증가하고, 메모리는 연간 7%씩 증가한다. 메모리는 크고 싸지만 느리고, 캐시는 작고 빠르고 비싸다.
Cache Basics
우선 캐시에 대한 내용을 먼저 이야기해보자. 캐시 메모리는 크기와 속도 면에서 메모리 계층 구조에 딱 들어맞는다. cacheline miss, page fault, HTTP request 모두 계층만 다르지 원리 자체는 똑같다. Squid 프록시가 캐시에 객체가 없으면 프록시는 서버로 요청을 보낸다. CPU가 메모리에 존재하지 않는 주소를 요청하면 page fault가 발생해서 디스크로부터 페이지를 읽어온다. CPU가 캐시에 존재하지 않는 주소에 접근하면 해당 캐시 라인를 메모리에서 읽어온다.
이 경우에는 더 작고 빠른 계층이 더 크고 느린 계층 위에서 돌아간다. 만약 더 느린 계층에서 실행하느라 성능이 제한된다면, 아무리 더 빠른 계층을 더더욱 빠르게 만들어도 성능 향상이 많이 이루어지지 않는다. (캐시를 제대로 활용하지 않으면 캐시의 성능이 좋아도 별 의미가 없다는 뜻)
캐시 메모리에서 가장 중요한 것은 캐시 라인이다. 일반적으로 캐시 라인의 크기는 32 or 64 바이트이고, 캐시 라인 크기로 정렬되어있다. 접근하는 메모리가 캐시에 존재하지 않으면 메모리로부터 캐시 라인으로 불러오는데, 이것이 캐시 미스이다. 캐시 미스가 발생하면 메모리로부터 불러오는 속도 때문에 지연된다. 하지만 캐시 라인에 불러온 이후에는 메모리에 접근하지 않고 캐시에서 바로 불러올 수 있으므로 캐시 라인을 버리기 전까지는 빠르다. 만약 캐시 라인이 사용되지 않거나 서로 다른 메모리가 같은 캐시 라인을 사용하면 현재의 캐시 라인은 버려지고 다른 메모리의 내용을 새로 불러오게 된다. 그리고 캐시 라인에 존재하는 데이터가 변경되면, 캐시 라인을 버릴 때 메모리와 동기화를 해야한다.
여기까지가 캐시에서 가장 단순하지만 중요한 내용이다. 여기엔 두 가지 교훈이 있는데, 최대한 많은 데이터를 하나의 캐시 라인에 포함되게 하고, 최대한 적은 캐시 라인을 사용하는 것이다. 그렇게 함으로써 메모리가 늘어나도 캐시를 잘 활용할 수 있게 된다. 하지만 더 복잡한 캐시의 특성은 바로 thrashing이다. 캐시 라인의 경쟁이 심해질수록 성능은 드라마틱하게 나빠진다. 글에 뒷부분에서 thrashing에 대해 더 자세하게 다룬다.
The Pentium II L1 and L2 Caches
Pentium II의 32K L1 캐시는 32바이트 캐시라인 * 1024개로 이루어져 있다. 그리고 1024개중 512개는 데이터를 저장하기 위한 캐시이고, 512개는 인스트럭션을 저장하기 위한 캐시이다. 그리고 5번~11번 비트를 캐시 라인의 인덱스로 사용하고, 12번~31번 비트를 캐시 라인의 태그로 사용한다. 문서엔 딱히 언급은 안했지만 캐시라인 II는 캐시라인 하나가 32비트이므로 0번 ~ 4번 비트는 오프셋으로 사용될 것이다. L1 캐시는 4-way set associative mapping 방식을 사용하므로 512개의 캐시 라인은 4 캐시라인 * 128개 집합 으로 나뉘어진다.
31 - 12 11 - 5 4 - 0
[ tag bits ] [ index bits ] [ offset ]
각각의 집합은 LRU (Least Recently Used) 리스트이다. 따라서 이미 존재하는 캐시 라인에 접근하면, 해당 캐시 라인이 리스트의 맨 앞으로 이동하고 존재하지 않는 캐시 라인에 접근하면 메모리로부터 불러와서 리스트의 맨 앞에 넣는다.
같은 컬러를 가진 메모리는 4개의 L1 캐시 라인을 두고 경쟁한다. 이때 컬러가 같다는 것은 같은 인덱스를 가졌음을 말한다. 다르게 말하면 주소가 4096 ( 2^(7 인덱스 비트 + 5 오프셋 비트) )의 배수로 차이가 나면 서로 경쟁한다. 예를 들어 64와 12352는 차가 12288 = 3 * 4096이므로 같은 캐시 라인 집합 안에서 경쟁한다. 아래 그림을 보면 더 쉽게 이해할 수 있다.
인덱스는 특정 캐시 라인의 집합을 선택하는 데에 사용된다. 2-way set associative mapping에서는 한 집합당 2개의 캐시라인이 존재한다. 특정 주소가 캐시에 존재하는지 보려면 인덱스로 해당 집합에 접근한 뒤, 해당 집합에 현재 접근하려는 주소의 태그가 LRU 리스트에 존재하는지 찾아보면 된다.
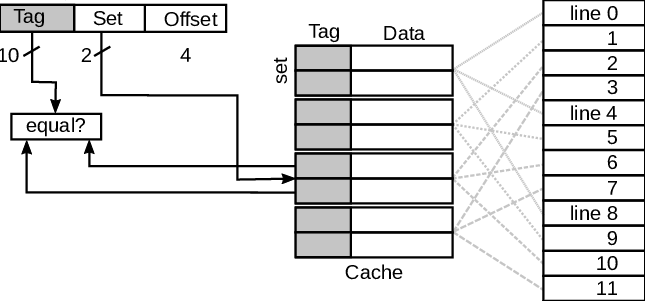
데이터 뿐만 아니라 인스트럭션도 캐시에 저장된다. Pentium II L1 캐시는 Harvard (instruction/data split) 캐시이다. 따라서 데이터와 인스트럭션은 서로 분리되므로 캐시 라인을 경쟁하지 않는다.
L2 캐시는 L1과 비슷하지만 더 크고 느리다. Pentium II에는 256K (8192 캐시라인) 캐시가 존재한다. L2도 L1과 마찬가지로 4-way set associative지만 데이터와 인스트럭션의 구분이 없다. L2 캐시에서는 64K (11 인덱스 비트 + 5 오프셋 비트)의 배수로 주소가 차이나면 같은 캐시라인을 경쟁한다. 왜 64K인지 덧붙이자면 캐시라인이 8192개 존재하는데 4-way set associative mapping이므로 2048개의 L1 caches가 하나의 set에 속한다. 따라서 set을 결정하는 인덱스 비트가 11비트이므로 64K가 된다.
Pentium II를 요약해보면:
- 캐시라인은 32바이트이고 32바이트 정렬이 되어있다.
- 메모리의 주소가 4K의 배수만큼 차이나면 같은 4개의 L1 캐시 라인을 두고 경쟁한다.
- 메모리의 주소가 64K의 배수만큼 차이나면 같은 4개의 L2 캐시 라인을 두고 경쟁한다.
- L1은 데이터와 인스트럭션 캐시가 분리되어있다 (Harvard)
- L2는 데이터와 인스트럭션이 캐시를 공유한다 (Unified)
Variable Alignment
캐시에 대해 대강 알아봤으니 변수의 정렬부터 알아보자. 정렬할 때는 항상 long word에 맞춰서 정렬하는 것이 좋다.

리눅스는 gcc로 컴파일하는데, gcc는 d_reclen을 long에 맞춰서 자동응로 정렬해준다. unsigned short 같은 경우에는 별 문제가 없는데, short 같은 경우에는 부호를 처리하는 인스트럭션이 들어가서 텍스트 섹션의 크기가 커진다. 따라서 필요한 경우가 아니라면 short보단 unsigned short나 int로 쓰는 것이 좋다. 예를 들어서 <linux/mm.h>의 vm_avl_height를 unsigned short로 바꾸면 32바이트의 인스트럭션을 아낄 수 있다.

그리고 문자열도 정렬을 하면 더 값싼 SIMD 명령으로 비교할 수 있다. .align 4로 모든 문자열을 정렬했을 때 약 8K를 절약할 수 있다.
Cache Alignment of Structures
배열과 구조체에는 많은 데이터가 함께 존재하므로 캐시 라인에 맞춰 정렬할 여지가 있다. 자주 접근되는 필드는 하나의 캐시라인 안에 넣는 것이 효율적이다. (메모리로부터 한 번만 불러오므로) 따라서 지연 시간도 줄고 cache footprint도 줄일 수 있다. 많은 데이터에 접근할수록 cache footprint가 증가하므로, 효율적으로 하나의 캐시라인에 집어넣는 것과 cache pollution을 모두 고려해야 한다. 여기서 cache pollution은 불필요한 데이터로 캐시를 채우는 것을, cache footprint는 프로그램이 사용하는 캐시의 양을 의미한다.
배열의 시작 주소는 항상 캐시 라인에 맞춰 정렬되어야 한다. 또한 구조체의 크기도 캐시 라인의 배수이거나 캐시 라인의 크기를 나눴을 때 딱 떨어지는 값이어야 한다. 비슷하게 배열의 각 원소도 캐시 라인에 맞춰서 정렬되어야 한다. 링크드 리스트도 비슷하지만 링크드 리스트에서는 크기 제한이 없다.

32비트 Pentium에서는 mem_map_t가 72바이트이다. 2.2.16에서는 40바이트였다. 근데 mem_map_t를 할당할 때 sizeof(mem_map_t)를 기준으로 정렬하기 때문에 배열의 시작 주소가 제대로 정렬되지 않는다. 따라서 MAP_ALIGN을 L1_CACHE_ALIGN으로 대체하면 L1 캐시 라인에 맞춰 정렬할 수 있다.

64비트 Alpha 프로세서에서는 long이 8바이트이고 sizeof(mem_map_t)가 144 = 8 * 18이다. flags는 long일 필요가 없고 int여야 한다. 그러면 atomic_t도 int이므로 flags와 count가 하나의 캐시 라인에 들어갈 수 있다. 그리고 wait_queue_head_t wait;은 원래 포인터였는데 지금은 아니다. 다시 포인터로 바꾸면 32비트와 64비트 모두에서 정렬하기가 쉬워진다.
Cache Line Alignment for Different Architectures
프로세서마다 캐시 라인의 크기가 다른데 리눅스는 다양한 프로세서를 지원한다. 그럼 어디에 맞춰서 정렬해야할까? 여기서 저자는 가장 흔한 32바이트에 맞추는게 좋다고 하는데, 요즘은 64비트에 맞추는 것 같다. 지금 이 글을 쓰는 내 컴퓨터의 L1 캐시 라인 크기도 64바이트이다.
Cachng and the Linux Scheduler
리눅스는 각각의 프로세스를 task_struct로 표현한다. 그리고 각각의 프로세스는 2개의 4K 페이지를 할당받는다. 태스크 리스트는 모든 프로세스를 관리하는 링크드 리스트이다. 그리고 runqueue에는 실행 가능한 모든 프로세스가 task_struct의 리스트로 연결되어있다. 스케줄러는 매번 실행할 프로세스를 찾느라 runqueue를 순회해야한다. (세상에! 이때는 Ingo Molnar가 O(1) 스케줄러를 만들기 이전이었다. O(n) 스케줄러라니!)
따라서 수천개의 스레드를 실행할 때는 스케줄링의 오버헤드가 매우 컸다. 특히 UP에서 자바 스레드를 돌릴 때는 스케줄러의 오버헤드가 25%나 되었다. SMP에서 메모리를 공유할 때는 문제가 더 심각해진다. 확장성이 전혀 없다.
근데 스케줄러에서 goodness() 루틴이 불필요하게 task_struct상의 여러 개의 캐시 라인을 접근하는 것으로 밝혀졌다. 이걸 발견한 후에 자주 접근되는 필드를 하나의 캐시 라인으로 넣었더니 cpu cycle이 179 -> 115로 줄었다.


스케줄러는 runqueue를 순회하면서 적합한 프로세스를 찾아서 실행한다. goodness() 루틴을 보면 goodness에서 counter와 run_list를 자주 접근하는데 둘이 서로 다른 캐시라인에 있는걸 볼 수 있다.
그리고 스케줄링할 때 프로세스는 마지막 실행한 프로세서와 같은 프로세서에서 실행할 경우 캐시라인의 재사용을 기대할 수 있다. 다만 리눅스 스케줄러는 버그가 있는데, runqueue에 프로세스가 없을때 다른 CPU에서 돌아가고 있는 프로세스를 할 일이 없는 프로세서로 옮긴다. 프로세서에게 일을 분배하는 것도 좋지만 CPU간에 프로세스가 이동하는 것보단 가능하면 불균형이 생기더라도 같은 CPU에서 돌아가는 것이 좋을 수 있다.
Cache Line Prefetching
prefetch는 사용할 것이라고 예상되는 미리 캐시라인을 불러오는 것이다. 최근에는 많은 CPU가 인스트럭션을 prefetch하지만 데이터는 잘 하지 않는다. (인스트럭션이야 뭐 당연히 다음 인스트럭션을 prefetch하면 되겠지만 데이터는 꼭 그럴것이라고 단정지을 수 없다.) 캐시 라인의 여유에 따라서 하나 또는 그 이상의 캐시라인을 미리 prefetch할 수 있다. 충분히 미리 prefetch를 하면 L2 캐시가 아닌, 메모리에 있는 데이터라도 충분히 prefetch를 할 수 있다.
prefetching은 일반적으로 어느 데이터가 prefetch 해야할지 알기 쉬운 멀티미디어 커널과 행렬 연산에서 사용되어왔다. 자료 구조를 사용하는 알고리즘에서도 prefetch를 할 수 있다. prefetch할 주소를 계산하는 게 아니라 링크드 리스트를 따라간다는 점을 제외하고는 똑같다.
prefetching은 지연 시간의 감소보다는 메모리에 접근하는 대역폭이 증가하기 때문에 중요하다. 데이터 구조를 순회하는 것은 지연 시간 문제가 발생할 확률이 더 높다. 자료 구조에서는 일부 필드만 자주 접근하지만 멀티미디어는 모든 데이터에 접근한다는 점이 다르다.
Prefetching From Memory
prefetch가 20 ~ 25개 정도의 인스트럭션을 앞서서 실행된다면 fetch가 인스트럭션 실행과 완전히 겹쳐서 실행될 수 있 다. 그리고 요즘 프로세서는 파이프라이닝으로 동시에 여러 인스트럭션을 실행하기 때문에 prefetch가 더 잘 될 것이다.
Prefetching From L2
어떤 알고리즘이 L2 캐시에 존재할 확률이 높은 데이터에 접근하면, L2 캐시가 메모리 보다 속도가 빠르므로 6~10 인스트럭션 먼저 prefetch를 하면 된다. 리눅스의 스케줄러 루프는 prefetch의 좋은 예시인데, goodness()가 실행시간이 짧고 IBM이 수정한 이후로는 task_struct의 counter와 run_list가 같은 캐시라인에 존재하기 때문이다.

Caches and Iterating Through Lists
자주 리스트를 순회할 때는 캐시를 주의깊게 고려해봐야 한다. 원소가 많아질수록 많은 캐시라인에 접근하므로 thrashing이 많이 발생하게 된다. thrasing의 증가로 인한 성능 저하는 발견하기 어렵다.
리눅스 스케줄러는 다음 실행할 프로세스를 찾을 때 runqueue를 순회한다. 이때 for_each_task 매크로를 사용한다. 리스트를 순회하면 메모리의 트래픽과 cache footprint가 증가한다.
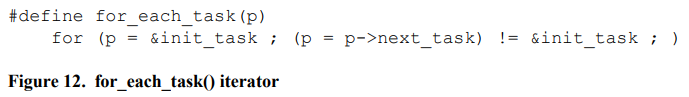
for_each_task는 CacheLine_Prefetch를 사용할 수 있다. next_task는 캐시 라인에 존재하지 않을 확률이 높으므로 메모리 트래픽과 cache footprihnt가 두배가 된다.


그리고 리눅스 스케줄러는 task queue가 아니라 runqueue를 순회해야 한다. 이것도 성능에 좋지 않다.

또 리눅스는 get_pid에서도 for_each_task를 사용하는데 이때 task_struct의 다양한 필드에 접근하므로 캐시 라인을 고려해서 몇몇 필드를 다시 패치해야 한다. 커널의 pid_t는 4바이트 int인데 PID_MAX는 0x8000이므로 unsigned short로 줄일 수 있다. priority는 0 ~ 40 사이이고 counter는 priority로부터 만들어진다. policy는 6개의 값만 표현하면 되고 processor는 NR_CPUS가 32이므로 unsigned short를 사용할 수 있다. 따라서 다음과 같이 필드를 재배치할 수 있다.

가능하면 루프에서 접근하는 필드들은 최소한의 캐시라인 안에 모두 끼워넣는 것이 좋다. 반드시 short를 써야하는 이유가 있다면 short를 써도 좋다. 그리고 캐시 라인에 끼워맞출 수 있다면 비트 단위로 데이터를 저장해도 좋다. 그리고 데이터를 32바이트 안에 표현할 수 없다면 자료구조 자체를 다시 재구성해보는 것도 좋다.
Thrashing
이제 thrashing에 대해서 알아보자. 전보다 복잡하니 조심하자. task_struct는 4K 정렬된 두 개의 페이지를 사용한다. L1 캐시는 32비트 주소 공간을 4개의 캐시 라인을 갖는 128개의 그룹으로 나눈다. 만약 두 주소가 4K의 배수 만큼 차이가 난다면 4-way set associative L1 캐시에서는 4개의 캐시 라인을 두고 경쟁한다. 따라서 태스크 리스트를 순회하면서 task_struct를 접근하면 4개의 캐시라인 밖에 활용할 수 없다. 지금(2021)은 task_struct를 슬랩 할당자로 관리하지만 이때는 페이지 안에 두었던 것 같다. 그럼 서로 다른 페이지에 존재하는 task_struct는 모두 같은 위치에 존재하기 때문에, 그리고 페이지의 주소는 딱 4K로 정렬되어있기 때문에 이런 문제가 발생한다.
그리고 이건 L2에서도 크게 다르지 않다. task_struct가 4K 정렬이 되어있기 때문에 L2의 인덱스 비트중 5-11은 고정이다. 따라서 인덱스 비트의 4비트만 다르기 때문에 16 * 4 = 64개의 캐시라인을 두고 경쟁한다. 정리하면 task_struct를 순회하는 것은 L1 캐시에서 4개의 캐시라인을, L2 캐시에서 64개의 캐시라인을 두고 경쟁한다. 이렇게 보면 지금 task_struct를 슬랩으로 관리하는건 되게 현명한 선택이 아닌가..
그리고 더 심각한 것은 L2 캐시가 LRU 방식으로 동작한다는 점이다. runqueue를 순회하다보면 서로 다른 64개 이상의 task_struct를 순회할 때 *항상* 캐시 라인을 thrashing하게 된다. 이러면 prefetching을 해도 의미가 없다. 그리고 심지어 64개의 캐시라인이긴 하지만 항상 64개를 모두 사용할 수는 없기 때문에 더 심각하다. (사실 64개가 아니라 16 * 4개 이므로... 어떤 페이지에 할당하느냐에 따라 모두를 활용하지 못할 수 있다.)
근데 더 심각한 게 있다. TLB를 언급하는걸 까먹었다. 커널의 논리적 주소는 2단계 페이징을 통해 물리적 주소로 매핑된다.

이 매핑을 매번 계산하는 건 비용이 큰데, 이 비용을 절약하기 위해 계산의 결과가 TLB에 캐싱된다. Pentium II는 TLB가 Harvard 4-way set associative 캐시이다. (데이터 엔트리 64개, 인스트럭션 엔트리 32개) TLB도 LRU 방식으로 작동한다. TLB에서 매핑을 찾지 못하면 TLB miss가 발생하는데 이 비용은 프로세서에 따라 5 ~ 60 cpu cycle 정도이다.
페이지는 4K이므로 task_struct의 페이지는 항상 4개의 TLB 엔트리를 두고 경쟁한다. 여러 페이지를 순회하는 건 TLB를 생각했을 때 최악의 케이스이다. 순회를 하다보면 TLB miss가 점점 발생하게 된다. 근데 runqueue의 용도를 생각해보면 TLB를 아예 활용하지 못할 수도 있게 된다. 그리고 리눅스는 컨텍스트 스위칭을 할때마다 TLB를 비우는데 그럼 runqueue의 크기와 관계없이 TLB miss가 엄청나게 된다. 게다가 TLB miss는 cache miss와 동기적이기 때문에 prefetch도 무시된다. (이건 무슨 말인지 아직 잘 모르겠다.)
따라서 TLB를 생각했을 때 4K 페이지를 순회하는건 최대한 피해야한다. 주소가 캐시 라인 사이즈의 2^n배 만큼 차이가 날수록 캐시라인의 경쟁이 심해지고 (그만큼 많은 인덱스 비트가 고정되므로) 페이지 사이즈의 2^n 배만큼 차이가 날수록 TLB 엔트리를 경쟁하게 된다. 그리고 시스템에 따라서 L2 캐시를 추가하는 건 가능하지만 TLB는 확장할 수도 없다.
Pollution
어플리케이션은 prefetch로 더 빠르게 메모리에 접근할 수 있다. 하지만 한 번 접근한 후에 어떤 메모리는 더이상 접근하지 않는다. 이러한 메모리는 앞으로 사용되지 않을 캐시라인을 차지하는데, 이렇게 사용되지 않을 캐시라인은 비워줘야 한다. 성능을 생각하면 prefetch도 중요하지만 cache pollution도 피해야 한다.
예를 들어서, task_struct에는 캐시 라인과 관련된 문제가 있다. for_each_task는 모든 태스크를 순회하면서 더이상 접근하지 않을 메모리가 캐시라인을 차지하면서 L2 캐시를 오염시킨다. 이렇게 사용되지 않을 캐시라인은 나중에 더 많은 cache miss를 발생시킨다.
Pentium II에서는 non-temporal prefetchnta 인스트럭션이 존재한다. 이 인스트럭션은 데이터를 캐시 라인을 L1로 불러오는데, L2에 있으면 L2에서 불러오지만 L2에 없으면 L2에 불러오지 않고 L1으로 바로 불러온다. 따라서 L2 캐시의 오염이 적게 일어난다.

False Sharing
thrashing의 변형은 False Sharing이다. 두 개의 변수가 같은 캐시 라인에 들어있는데 각 변수를 서로 다른 CPU에서 갱신하면 서로의 캐시를 invalidate하기 때문에 엄청난 성능 저하가 발생한다. (캐시 동기화 문제) 따라서 서로 다른 CPU가 접근할 수 있는 데이터는 서로 다른 캐시라인에 두어야 한다. 아래의 예제에서는 per-cpu 배열의 각 원소를 캐시라인에 맞게 정렬한다.

Page Coloring
64K만큼 차이가 나는 두 메모리 라인은 4개의 L2 캐시 라인을 두고 경쟁한다. 반대로 64K 범위 안에 속한 메모리 라인들 끼리는 경쟁하지 않는다. 이 64K를 16 * 4K 페이지로 나누면, 각각의 페이지는 고유한 컬러를 갖는다. 서로 다른 컬러의 페이지는 서로 경쟁하지 않는다.
따라서 만약 두 개의 페이지를 동시에 접근해야 한다면 서로 다른 컬러의 페이지를 접근하는 것이 좋다. 특히 n-way set associated mapped 캐시가 아니라 direct mapped 캐시에는 캐시 라인이 하나만 있어서 이런 경쟁을 줄일 필요가 있다. FreeBSD는 페이지의 컬러를 고려해서 할당하려고 시도하고, 리눅스는 페이지 컬러링의 비용이 너무 커서 지원하지 않는다.
Constraints
정렬이 된 데이터는 그만큼 더 적은 인덱스 비트를 사용하기 때문에 정렬 단위가 클 수록 사용할 수 있는 캐시라인이 제한된다(Constrained). 예를 들어서 task_struct에서는 64개의 캐시 라인이 서로 경쟁한다. 이런 경우에는 task_struct를 슬랩에서 할당하는 것이 좋을 것이다. (그리고 그것이 실제로 일어났다)
슬랩은 페이지를 쪼개서 오브젝트를 할당하기 때문에 task_struct를 슬랩에서 할당받게 하면 순회할 때 TLB miss가 더 적게 일어날 것이다. (오브젝트들이 같은 페이지에 존재하므로). 그리고 슬랩은 또 내부에서 컬러링을 하기 때문에 캐시를 더 효율적으로 사용할 수 있다.
Back To The Future
스케줄러의 예시에서 해결 방법은, 정렬된 구조체의 배열은 구조체의 크기가 캐시 라인의 홀수배이면 제한 문제가 사라진다. (이 부분은 왜인지 정말 모르겠다. 왜지?)

In Summary, You Are Doomed
Alignment and Packing
호환성 있는 프로그램을 짠다면 32바이트 캐시라인을 가정하자. 배열에 대해서는 배열의 시작 주소는 캐시 라인 크기로 정렬되어야 한다. 그리고 구조체의 크기는 캐시 라인 크기의 배수거나 딱 떨어지는 수여야 한다. 그러면 배열의 원소도 모두 캐시 라인 크기로 정렬이 된다. 링크드 리스트 같은 경우에도 비슷하지만 크기에는 제한이 없다. gcc에서 구조체를 정렬하려면 aligned 속성을 사용하면 된다. 사용자 어플리케이션에서는 malloc(size) 대신 memalign(32, size)를 사용하자.

Cache Footprint
the Elements of Style에서는 다음과 같이 말한다.
• Omit needless words. (필요없는 데이터를 줄이자)
• Keep related words together. (관련된 데이터를 하나의 캐시라인에 넣자)
• Do not break cache lines in two. (캐시 라인을 둘로 나누지 말자)
• Avoid a succession of loose cache lines. (이건 무슨 말일까)
• Make the cache line the unit of composition. (캐시 라인을 구성의 단위로 생각하자)
커다란 배열이나 리스트를 순회할 때는 캐시를 고려하자. 원소의 수가 많아질수록 캐시 라인이 부족해지면 thrashing이 발생한다.
그리고 일단은 페이지 컬러링 문제는 생각하지 말자. 많은 양의 메모리를 스캔하면 캐시를 비워주자. 그리고 많은 양의 메모리를 복사할 때도 캐시를 비워주자. 두 작업 모두 캐시를 오염시킨다.
불필요한 데이터로 캐시를 오염시키지 말자. 캐시 라인의 데이터에 다시 접근할 일이 없다면 비워주자. 많은 양의 데이터에 접근할 일이 있다면 non-temporal prefetch로 L2 캐시 오염을 예방할 수 있다.
인터럽트 핸들러는 non-temporal prefetch, 캐시 비우기, 그리고 streaming store 인스트럭션으로 캐시 오염을 방지해야 한다.
공유 라이브러리는 많은 프로세스가 같은 인스트럭션 메모리를 공유하도록 한다. 따라서 캐시의 경쟁을 줄이고 캐시를 공유할 확률이 높아진다.
Prefetch
하나의 캐시라인에서 작업한 후, 다음 캐시라인으로 넘어간다면 다음 캐시라인을 미리 prefetch하자. 그러면 메모리의 대역폭을 늘리고 메모리 지연 시간이 줄어든 것 처럼 보이게 된다.
메모리를 prefetch하는 데에는 20~25 인스트럭션 정도가 걸리고, L2 캐시를 prefetch하는 데에는 6~10 인스트럭션 정도가 걸린다. 참고하자.
Worst Case Scenarios
캐시를 매우 비효율적으로 사용하는 경우를 피하자. n-way set associative 캐시에서는 주소가 캐시 라인 크기의 2^n배 (64, 128, 256, ...) 만큼 차이가 나면 그만큼 인덱스 비트가 고정되므로 더 적은 캐시라인 안에서 경쟁한다.
비슷하게 주소가 페이지 크기의 2^n배 만큼 차이가 나면 더 적은 TLB 엔트리를 두고 경쟁하게 된다.
False Sharing - 여러 CPU 사이에서 공유하는 캐시라인에 있는 데이터를 갱신하지 말자
Constraints - 작은 객체의 할당은 캐시 컬러링으로 캐시 라인 경쟁을 피하자. (슬랩 할당자) 그리고 구조체 배열에 대해서는 구조체의 크기를 캐시 라인 크기의 홀수 배로 만들자.
Coloring - 필요한 경우에는 페이지를 컬러를 고려해서 할당하자. 간단하게 16, 32, 48, ... 등으로 페이지를 한꺼번에 할당하면 컬러가 균일하게 페이지를 할당할 수 있다.

References
Jeff Bonwick, The Slab Allocator: An Object-Caching Kernel Memory Allocator, Usenix Summer 1994 Technical Conference, 1994.
Ray Bryant and Bill Hartner, Java technology, threads, and scheduling in Linux: Patching the kernel scheduler for better Java performance, IBM Developer Works, January 2000.
Cort Dougan, Paul Mackerras and Victor Yodaiken, Optimizing the Idle Task and Other MMU Tricks, Third Symposium on Operat-ing Systems Design and Implementation, 1999.
Jim Handy, The Cache Memory Book, 2nd edition, Academic Press, 1998.
John Hennessy and David Patterson, Computer Architecture, 2nd edition, Morgan Kauffman, 1996.
Peter Honeyman et al, The Linux Scalability Project, University of Michigan CITI-99-4, 1999
Ingo Mulnar, http://people.redhat.com/mingo/mmx-patches/
Intel Architecture Optimization Reference Manual, developer.intel.com, 1999.
Block Copy Using Intel Pentium III Processor Streaming SIMD Extensions, developer.intel.com, 1999.
William L. Lynch, The Interaction of Virtual Memory and Cache Memory, Stanford CSL-TR-93-587, 1993.
Scott Maxwell, Linux Core Kernel Commentary, Coriolis, 1999.
Kirk McKusick et al, The Design and Implementation of the 4.4BSD Operating System, Addison Wesley, 1996.
Curt Schimmel, UNIX Systems for Modern Architectures: Symmetric Multiprocesssing and Caching for Kernel Programmers, Addison Wesley, 1994.
Julian Seward, Cacheprof, www.cacheprof.org
Tom Shanley, Pentium Pro and Pentium II System Architecture: 2nd edition, Mindshare, 1997
Richard Stallman, Using and Porting GNU CC: for version 2.95, Free Software Foundation, 2000
Strunk and White, The Elements of Style, 4th edition, Allyn and Bacon, 1999.
'Computer Architecture' 카테고리의 다른 글
| 다시 정리하는 NUMA (1) | 2022.01.21 |
|---|---|
| LEGv8 ISA - 특징과 명령어 포맷 (0) | 2021.12.02 |
| Instruction Set Architecture vs Microarchitecture (0) | 2021.12.01 |
| 메모리 계층별 대략적인 성능 비교 (0) | 2021.11.07 |
| NUMA: Non-Uniform Memory Access (0) | 2021.09.30 |




댓글