이 글은 Mel Gorman의 Understanding The Linux Virtual Memory Manager의 일부를 정리한 것이다. 최신의 가상 메모리 서브시스템과는 내용이 상이할 수 있다. 하지만 기본 개념을 설명하기엔 충분하다고 생각한다. 최신 내용은 필요에 따라서 별도로 글로 정리할 생각이다.
Node
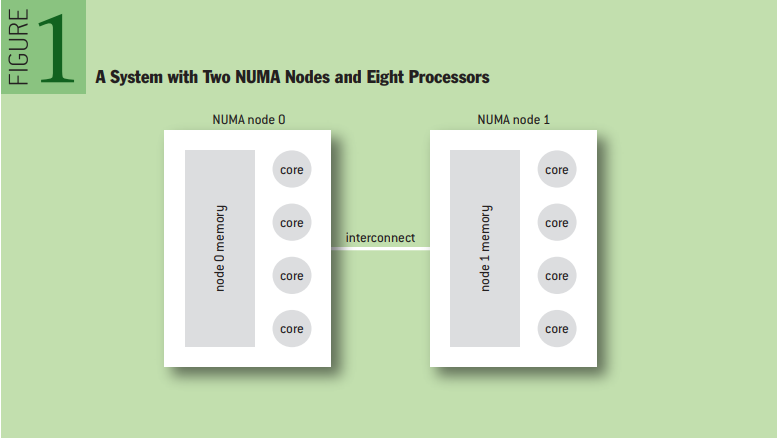
메모리의 접근 속도가 균일하지 않은 시스템을 NUMA 시스템이라고 한다. 자세한 건 NUMA 글을 참고하자. NUMA 시스템에서 같은 특성(접근 속도)을 갖는 메모리를 노드라고 한다. 예를 들어서 프로세서 2개(각각 4코어)와 노드 2개가 있을 때는 프로세서에 기준으로 자신에게 가까운 노드(local node)에 접근하는 속도는 빠르고, 먼 노드(remote node)에 접근하는 속도는 느리다. 운영체제는 remote node access로 인한 페널티를 줄이기 위해 최대한 local node에서 메모리 할당을 하려고 노력한다.
struct pglist_data (pg_data_t) in include/linux/mmzone.h
리눅스는 노드에 대한 정보를 struct pglist_data로 정의한다. struct pglist_data의 정의는 매우 복잡하다. 예전 버전의 정의를 가져왔다. 이해하는 데에는 크게 달라진 점이 없으므로 이 버전으로 살펴보자.
129 typedef struct pglist_data {
130 zone_t node_zones[MAX_NR_ZONES];
131 zonelist_t node_zonelists[GFP_ZONEMASK+1];
132 int nr_zones;
133 struct page *node_mem_map;
134 unsigned long *valid_addr_bitmap;
135 struct bootmem_data *bdata;
136 unsigned long node_start_paddr;
137 unsigned long node_start_mapnr;
138 unsigned long node_size;
139 int node_id;
140 struct pglist_data *node_next;
141 } pg_data_t;node_zones: 해당 노드에 존재하는 zone의 배열이다. zone은 다음 섹션에서 다룬다.
node_zonelists: 이 노드에서 페이지를 할당할 때, 할당을 시도하는 순서이다. (예를 들어 ZONE_HIGHMEM -> ZONE_NORMAL -> ZONE_DMA 순서로 시도한다는 등등)
nr_zones: 뒤에서 알아보겠지만, zone의 종류는 다양한데 항상 모든 zone이 존재하지는 않기 때문에, 해당 노드에 존재하는 zone의 개수를 나타낸다.
node_mem_map: 리눅스에서 모든 물리적인 page는 mem_map이라는 배열로 접근할 수 있다. (전역변수) 이때 node_mem_map은 mem_map 상에서 해당 노드에 해당하는 첫 번째 page의 주소를 가리킨다.
valid_addr_bitmap: 어떤 아키텍처에서는 주소 공간의 일부가 비어있을 수 있으므로 유효한 주소의 범위를 나타내는 비트마스크이다. 대부분의 아키텍처에서는 사용되지 않는다.
bdata: 부트 메모리 할당자에서 사용하는 부분인데 이 글에서는 다루지 않는다.
node_start_paddr: 노드의 첫 물리 주소를 나타낸다.
node_start_mapnr: 전역변수 mem_map 상에서의 오프셋을 나타낸다.
node_size: 노드에 존재하는 페이지의 숫자이다.
node_id: 노드의 id이다.
node_next: pglist_data는 마지막이 NULL인 linked list로 되어있다. node_next는 다음 노드(or NULL)를 가리키는 포인터이다.
struct pglist_data는 노드를 서술하는 디스크립터이며, 노드의 정보는 전역 변수로 존재한다. 이 전역 변수는 include/linux/mmzone.h의 NODE_DATA(nid) 매크로로 접근할 수 있다. 코드를 보면 UMA에서는 config_page_data라는 전역 변수로 접근하고, NUMA에서는 아키텍처마다 따로 구현하도록 되어있다.
1087 #ifndef CONFIG_NUMA
1088
1089 extern struct pglist_data contig_page_data;
1090 static inline struct pglist_data *NODE_DATA(int nid)
1091 {
1092 return &contig_page_data;
1093 }
1094 #define NODE_MEM_MAP(nid) mem_map
1095
1096 #else /* CONFIG_NUMA */
1097
1098 #include <asm/mmzone.h>
1099
1100 #endif /* !CONFIG_NUMA */Zone
앞서 알아본 노드는 물리적인 특성에 따라(접근 속도) 메모리의 영역을 분리한 것이다. 하지만 접근 속도 말고도 다양한 특성에 따라 메모리 영역을 분리할 필요가 있다. 이것을 존(Zone)이라고 한다.

시스템 전체로 봤을 때는 노드가 가장 상위에 존재하고, 노드별로 존이 존재하며, 존마다 페이지가 존재한다.
struct zone_struct
37 typedef struct zone_struct {
41 spinlock_t lock;
42 unsigned long free_pages;
43 unsigned long pages_min, pages_low, pages_high;
44 int need_balance;
45
49 free_area_t free_area[MAX_ORDER];
50
76 wait_queue_head_t * wait_table;
77 unsigned long wait_table_size;
78 unsigned long wait_table_shift;
79
83 struct pglist_data *zone_pgdat;
84 struct page *zone_mem_map;
85 unsigned long zone_start_paddr;
86 unsigned long zone_start_mapnr;
87
91 char *name;
92 unsigned long size;
93 } zone_t;lock: zone_struct를 보호하는 spinlock이다.
free_pages: 존에 존재하는 free 상태의 페이지의 개수이다.
pages_min, pages_low, pages_high: 이 존 워터마크는 다음 섹션에서 설명한다.
need_balance: kswapd가 존의 밸런스를 맞춰야 할지를 나타내는 플래그이다. 밸런스가 맞춰진 상태인지 아닌지는 존의 워터마크에 따라 결정된다.
wait_table: IO 등의 특정 상황에서는 페이지를 잠시 사용하지 못하도록 잠근다. UnlockPage() 등으로 잠근 것을 해제하면 해당 페이지를 대기하던 프로세스들을 모두 깨워야 하는데, 프로세스들이 대기하는 wait queue에 대한 해시테이블이 바로 wait_table이다.
wait_table_size: 해시 테이블의 크기로, 2의 거듭제곱 형태이다.
wait_table_shift: 해시 테이블의 크기를 비트로 나타낸 것이다.
zone_pgdat: 존이 소속된 노드의 디스크립터에 대한 포인터이다.
zone_mem_map: 아까 설명한 node_mem_map과 같다.
zone_start_paddr: 아까 설명한 node_start_paddr과 같다.
zone_start_mapnr: 아까 설명한 node_start_mapnr과 같다.
free_area: 버디 할당자가 페이지를 할당할 때 사용하는 비트맵이다.
name: DMA, DMA32, NORMAL, HIGHMEM 등등 존의 이름이다.
size: 존에 존재하는 페이지의 개수를 나타낸다.
Zone의 워터마크
시스템에 메모리가 부족해지면 리눅스는 메모리 확보를 위해서 열심히 일한다. 리눅스에서 메모리의 확보는 kswapd가 담당한다. 위에서 살펴본 pages_min, pages_low, pages_high는 "이 정도면 메모리가 충분하다~", "이 정도면 메모리가 부족하다~" 라는 기준을 나타낸다.
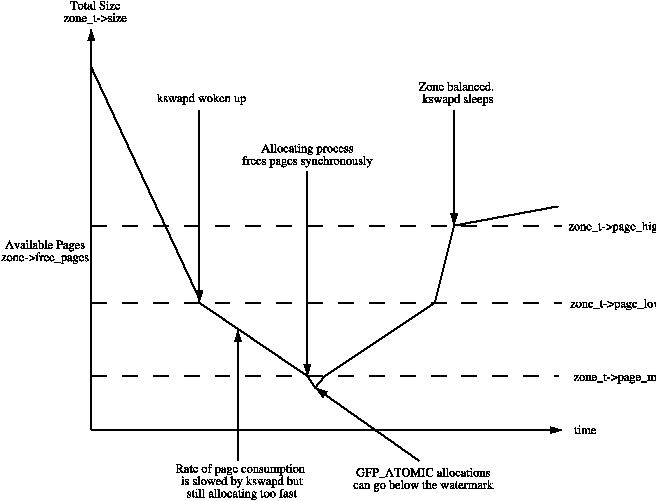
그림에서 보여주듯 kswapd는 free_pages가 pages_low에 도달하면 kswapd를 깨워서 메모리 확보를 시작한다. pages_min에 도달하면 메모리가 매우 부족하다는 뜻이므로 좀 더 열심히 memory reclaim을 수행한다. 그러다가 메모리가 충분해져서 pages_high에 도달하면 kswapd는 다시 일을 멈추고 잠에 든다.
참고 문서
https://www.kernel.org/doc/gorman/html/understand/understand005.html
Describing Physical Memory
PG_launderThis bit is important only to the page replacement policy. When the VM wants to swap out a page, it will set this bit and call the writepage() function. When scanning, if it encounters a page with this bit and PG_locked set, it will wait for the
www.kernel.org
'Kernel > Memory Management' 카테고리의 다른 글
| Virtual Memory: Transparent Huge Pages (0) | 2022.03.23 |
|---|---|
| Virtual Memory: Memory Compaction (0) | 2022.01.10 |
| Virtual Memory: Zone의 종류 (0) | 2022.01.03 |
| Virtual Memory: Grouping pages by mobility (0) | 2022.01.02 |
| Virtual Memory: Folio in 5.16 (1) | 2021.12.12 |




댓글