
이 글에서는 메모리 일관성 모델이 무엇이며, 컴퓨터 구조에서 store buffer와 invalidate queue가 어떤 역할을 하고, 메모리 접근 연산의 일관성을 어떻게 유지할 수 있는지 알아본다.
메모리 배리어도 자세하게 정리하려고 했으나 글 하나에 담기엔 너무 길어져서 따로 정리해야겠다.
용어 정리
글을 쓰다보니 용어 하나 하나의 의미를 구분하는 게 생각보다 중요했다. 용어를 헷갈리기 시작하면 내용 전체가 헷갈린다. 그러니 용어를 먼저 정리해보자.
program order, execution order, perceived order
[1]에서는 메모리 연산이 코드에 명시된 순서를 program order, 메모리를 참조 명령어들이 실행되는 순서를 execution order, 메모리 연산의 결과가 현재 CPU와 다른 CPU들에게 보이는 순서를 perceived order라고 한다.
Coherence vs Consistency
컴퓨터 아키텍처를 공부하다보면 coherence와 consistency라는 용어가 나온다. 영한사전을 펼쳐보면 둘다 일관성이라는 의미를 갖는다. 아키텍처에서는 두 용어의 의미가 살짝 다르다.
coherence는 같은 주소의 데이터에 대해서, 데이터를 읽었을 때 가장 최신의 데이터가 읽힘을 보장하는 것이다. 예를 들어 메모리 상의 어떤 주소 x에 대하여 CPU0의 L1 캐시에 최신 내용이 존재하더라도, CPU1이 주소 x를 읽었을 때 최신의 데이터가 읽혀야 한다. 이러한 것을 coherence라고 한다. 우리가 멀티 코어 프로세서들은 캐시 일관성 프로토콜 (Cache Coherence Protocol) (MOESI, MESI 등등)으로 CPU 사이에서 일관성을 유지한다.
이와 달리 consistency는 메모리 접근 연산이 다른 메모리 접근 연산에 대하여 일관되는 규칙대로 수행되는 것을 의미한다.
observer
이 글에서는 메모리를 읽고 쓸 수 있는 연산 유닛을 observer라고 한다. CPU, peripheral 등이 observer의 예이다. 이 글에서는 "~~가 observer에게 관찰되도록/보이도록 한다"라는 표현을 쓰지만, 데이터가 캐시에서만 갱신된 경우 peripheral에게는 관찰되지 않기 때문에 MMIO를 한다면 MMIO에 사용하는 버퍼가 캐싱되지 않도록 설정해야한다.
Memory Consistency Model
메모리 일관성 모델이 무엇일까?
In computer science, a consistency model specifies a contract between the programmer and a system, wherein the system guarantees that if the programmer follows the rules for operations on memory, memory will be consistent and the results of reading, writing, or updating memory will be predictable. - Wikipedia
위키피디아에서는 일관성 모델을 "프로그래머와 시스템의 약속으로, 프로그래머가 규칙을 지킨다면 시스템은 메모리가 일관적임을 보장해주고, 메모리를 읽고 쓰고, 갱신하는 연산을 예측 가능하게 해준다"라고 설명한다.
A memory consistency model is a contract between the hardware and software. The hardware promises to only reorder operations in ways allowed by the model, and in return, the software acknowledges that all such reorderings are possible and that it needs to account for them.
- https://www.cs.utexas.edu/~bornholt/post/memory-models.html
다른 문서에서는 조금 더 좁은 의미로, 메모리 일관성 모델은 "하드웨어와 소프트웨어 사이의 약속이며 하드웨어가 모델에서 허락하는 범위 안에서만 연산의 순서를 바꿀 수 있다"라고 설명한다.
간단하게 정리하면 메모리 일관성 모델은 "일관성있게 메모리를 사용하기 위한 규칙들의 집합"이라고 할 수있다. 규칙을 준수해서 메모리를 사용해야 일관성이 보장된다.
메모리 일관성 모델에 따라서 메모리 연산의 perceived order가 결정된다. 다르게 말하면 execution order가 같더라도, 시스템 내의 observer들이 메모리 연산의 결과를 관찰하는 순서는 메모리 모델에 따라서 다를 수 있다.
program order와 execution order는 달라질 수 있다. (Out-of-Order execution)
현대적인 프로세서에서 명령어를 실행할 때 instruction stream 상의 program order와 실제로 명령어가 실행되는 execution order는 다를 수 있다.
명령어의 program order와 execution order가 달라지는 이유는 성능 때문이다. 예를 들어 instruction pipeline 상에서 어떤 레지스터가 사용중인데, 다음에 처리할 명령어도 같은 레지스터를 사용해야 한다면 stall이 발생한다. 현대적인 프로세서에서는 명령어를 순서대로 실행하기보다 프로세서 내부의 처리 유닛을 최대한 활용하는 방향으로 명령어의 순서를 바꿔서 실행할 수 있다. [6]
execution order와 perceived order가 바뀌는 이유 (Store Buffer)
execution order와 perceived order가 달라지는 이유도 성능 때문인데, 구체적으로는 CPU가 쓰기 버퍼를 사용하기 때문이다. SMP 환경에서는 캐시의 일관성을 유지하기 위해 MESI, MOESI 등의 cache coherence protocol을 사용한다. 그런데 프로토콜에 따라 캐시에 데이터를 쓰려면, 쓰려는 캐시라인이 다른 CPU의 캐시에서 모두 invalidate 된 후에 데이터를 써야 한다.
그래서 현대적인 프로세서는 캐시에 바로 데이터를 쓰지 않고, 쓰기 버퍼에 먼저 쓴 후 나중에 다른 CPU의 캐시라인을 invalidate 하면서 캐시에 쓴다. 쓰기 버퍼의 특징은, 쓰기 버퍼는 CPU마다 있으며, 쓰기 버퍼에 기록된 내용은 아직 캐시에 쓰여지지 않기 때문에 다른 CPU에게는 보이지 않는다는 점이다.
그래서 쓰기 버퍼에는 execution order대로 기록되지만, 쓰기 버퍼의 내용이 캐시에 쓰여지는 순서는 달라질 수 있기 때문에 perceived order가 바뀌는 것이다. [2]에서 이 내용을 아주 잘 설명한다.
Invalidate Queues
하지만 쓰기 쓰기 버퍼는 쓰기 연산을 버퍼링해주는데, 쓰기 버퍼는 생각보다 작기 때문에 버퍼가 모두 차면 기존에 버퍼에 있는 데이터들에 대하여 다른 CPU들이 invalidate acknowledge를 해줄 때까지 기다려야 한다.
하지만 CPU의 캐시가 바쁜 경우에 invalidate acknowledge를 보내는 게 늦어질 수 있다. 따라서 현대적인 프로세서에서는 invalidate message를 받은 CPU가 실제로 캐시 라인을 invalidate를 한 후에 invalidate acknowledge를 하는 게 아니라, invalidate queue에 저장만 해두고 우선 invalidate acknowledge를 보낸다.
CPU가 로드 연산을 할 때는 invalidate queue를 확인하지 못하기 때문에, invalidate message를 받았더라도 stale한 데이터를 볼 수가 있다. 특히, 어떤 두 변수 사이에 의존성이 존재하는 경우에는 중간에 read or full memory barrier를 사용해서 invalidate queue에 존재하는 엔트리를 모두 처리해야한다.
Linux's memory model
리눅스와 같이 다양한 아키텍처를 지원하는 운영체제에서는 가장 느슨한 메모리 일관성 모델 (e.g. Alpha 프로세서의 메모리 모델)을 가정하고 코드를 작성해야 한다. 그래야 다양한 메모리 일관성 모델을 사용하는 프로세서 위에서도 코드가 잘 작동한다.
Compiler Optimization
참고로 메모리 일관성 모델과는 별개로 작성한 C언어 코드 순서와 program order가 다를 수 있는데, 그건 컴파일러도 명령어의 순서를 바꾸기 때문이다. 컴파일러 최적화도 주의해야 한다. 리눅스에서는 READ_ONCE()/WRITE_ONCE()/barrier()를 사용할 경우 컴파일러의 최적화를 막을 수 있다.
Memory Barrier
메모리 배리어는 배리어 이전의 메모리 접근이 배리어 이후의 메모리 접근보다 먼저 수행된 것으로 observer들에게 관찰되도록 한다. 즉, 메모리 연산의 perceived order를 강제한다. 메모리 배리어는 배리어 이전에 실행된 명령어가 와 배리어 이후에 실행된 명령어의 메모리 연산보다 항상 먼저 observer에게 관찰된다. 그리고 리눅스의 경우, 메모리 배리어에 컴파일러 배리어도 포함한다.
아래는 가상의 코드이다. 코드 중간에 메모리 배리어가 존재하기 때문에 시스템 내의 observer가 관찰하기에 c = 15와 b = 10의 순서는 바뀔 수 있지만, b = 10, c = 15는 배리어로 인하여 a = 5와 순서가 바뀌어서 관찰될 수 없다.
*강조하지만, 메모리 배리어는 메모리 연산 간의 perceived order를 강제하지만, 배리어 명령어를 실행하는 시점에 배리어 이전의 명령어의 메모리 연산이 완료됨을 보장하지는 않는다. 물론 일부 아키텍처에서는 메모리 연산의 완료를 보장하는 명령어를 지원하지만, 그렇지 않은 아키텍처도 존재하므로 아키텍처 외부의 코드에서는 그러한 가정을 해서는 안된다.
int x, y, z;
a = 5;
memory_barrier();
b = 10;
c = 15;
배리어는 양방향(two-way)이 아니라 단방향(one-way)일 수도 있다. 예를 들어 배리어 이전의 메모리 연산은 배리어 이후에 수행될 수 있지만, 배리어 이후의 메모리 연산은 배리어 이전에 수행될 수 없는 경우나 그 반대의 경우이다. 이 문단에선 배리어를 간단하게 설명하지만, 실제로는 아키텍처에 따라 더 다양한 종류의 배리어가 있다.
When does it matter
앞서 execution order와 perceived order가 달라지는 이유가 쓰기 버퍼의 내용은 그 쓰기 버퍼를 소유한 CPU에게만 보이며, 쓰기 버퍼의 내용이 캐시에 쓰여지는 순서가 다를 수 있기 때문이라고 했다.
하지만 쓰기 버퍼를 소유한 CPU는 캐시에서 데이터를 읽을 때 쓰기 버퍼도 확인하기 때문에 자연스럽게 execution order대로 연산이 보이게 된다. 메모리 연산의 재배치는 다른 observer와 자원을 공유할 때만 고려하면 된다. 리눅스는 이러한 상황을 위하여 SMP환경에서만 동작하는 배리어를 제공한다.
Synchronization Primitives
리눅스에서 스핀락, 뮤텍스, 세마포어, RCU 등 기본적으로 제공하는 synchronization primitive들은 메모리 배리어가 내장되어있다. 어떻게 생각하면 당연한데, 임계 영역 내의 코드가 재배치되어 락의 획득 이전에 실행된다면 exclusive하게 데이터에 접근하지 않을 수 있다. (끔찍하다)
따라서 synchronization primitive를 사용하지 않는 알고리즘을 구현할 때 더욱 메모리 모델을 고려해서 코드를 작성해야 한다. 또 MMIO를 할 때와 같이 메모리 접근 자체가 side effect를 일으키는 경우에도 배리어를 적절히 사용해야 한다.
Memory Ordering on Various Architectures

위 표는 [1]에서 빌려온 것이다. 처음 네 행은 load 연산 뒤로 store 연산을, load 연산 뒤로 load 연산을, store 연산 뒤로 store 연산을, store 연산 뒤로 load 연산을 재배치할 수 있는지 여부를 나타낸다. 나머지 두 행은 원자적 명령어의 메모리 연산과 load/store 연산의 순서가 바뀔 수 있는지를 나타낸다.
Dependent loads reordered
그 다음 "Dependent Loads Reordered?"는 의존성이 있는 load 메모리 연산들이 재배치될 수 있는지를 의미한다 (?!) 여기서 말하는 의존성은 address dependency이다.
알파 프로세서는 유일하게 address dependency가 있는 로드 연산들을 순서대로 수행하지 않을 수 있다. (주의: 다음 예시는 UP 환경에서는 발생하지 않는다.) 예를 들어서

위 코드에서 CPU0이 p (p가 가리키는 주소가 1000이라고 해보자)를 할당한 후 p->next, p->key, p->data를 초기화한다. 그 다음 smp_wmb()가 있기 때문에 p의 필드들이 초기화한 것이 head.next = p보다 먼저 캐시에 쓰이게 된다. 그리고 CPU0은 다른 CPU들에게 p->next, p->key, p->data를 포함하는 캐시라인을 invalidate하라고 메시지를 보낸다.
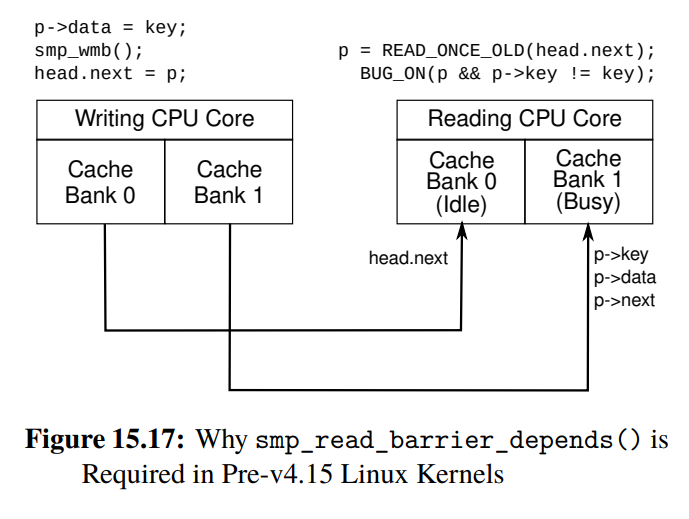
만약 위의 그림처럼 head.next가 뱅크0에 있고, p->key, p->data, p->next가 뱅크1에 있다고 하자. CPU1이 search를 수행할 때 CPU0이 invalidate를 하기 이전의 값이 p가 캐시에 저장되었다고 해보자.
위 사진에서 뱅크 0은 한가하기 때문에 head.next를 바로 읽어오지만, 뱅크 1은 바쁜 상태라서 invalidate를 아직 처리하지 않은 채로 invalidate하기 이전의 값을 CPU0이 읽는다.
이러한 현상이 알파 프로세서에서 일어날 수 있는 이유는, 알파 프로세서가 head.next ( = p)의 로드와 p->key의 로드 사이에 address dependency가 있음을 이해하지 못할 수 있기 때문이다. 만약 두 로드 사이에 의존성이 있음을 이해했다면 p->key를 로드할 때 invalidate queue에 head.next (= p)의 주소에 대한 invalidate 메시지가 존재함을 확인한 후 캐시 라인을 다시 읽어왔어야 한다.
조금 더 부가 설명을 적어보면, TSO platform의 경우에는 로드 연산과 로드 연산 사이의 순서를 보장하고, 좀 더 Weakly ordered platform의 경우에는 address dependency를 검출하는 하드웨어가 존재하지만 알파 프로세서는 load-to-load address dependency를 검출하지 못한다. [6의 Quick Quiz 15.15 참조]
리눅스 v4.15 이전에는 다른 CPU가 수정할 수 있고 데이터 의존성이 존재하는 변수들을 읽는 경우 {smp_,}read_barrier_depends() 등의 데이터 의존성 배리어를 사용해주어야 했다. 리눅스 v4.15 이후에는 alpha의 READ_ONCE()에 mb()를 추가해버려서 커널 코어에서 데이터 의존성 배리어를 고려하지 않아도 되도록 바뀌었다. 이후 커널에서는 데이터 의존성 배리어 자체가 제거되었다.
Incoherent Instruction Cache/Pipeline
마지막으로 "Incoherent Instruction Cache/Pipeline?"은 명령어 캐시와 데이터 캐시가 coherent한지를 의미한다. 예를 들어 ARMv8-A의 경우에는 instruction cache와 data cache가 coherent하지 않기 때문에, self-modifying 코드와 같은 경우 명령어 캐시와 데이터 캐시를 동기화를 하는 명령어가 존재한다. (Point of Unification)
좀 더 부가설명을 하자면, 어떤 코드가 코드 섹션을 수정하는 경우, store 명령어로 수정하기 때문에 이는 데이터 캐시에 저장된다. 만약 CPU0이 수정한 코드를 CPU1이 load 명령어로 읽는다면 CPU 사이에서 데이터 캐시는 coherent하기 때문에 CPU1이 최신 내용을 읽을 수 있지만, CPU0이 수정한 코드를 CPU1이 명령어를 fetch하여 실행한다면 데이터 캐시와 명령어 캐시가 coherent하지 않으므로 CPU1은 최신의 코드를 실행할 수도, 아닐 수도 있다.
따라서 self-modifying 코드 뿐만 아니라 exec(), 코드 섹션에 대한 page fault 등 코드를 메모리에 쓴 후 실행하는 경우도 데이터 캐시와 명령어 캐시 간의 coherence를 고려해야 한다. [1]

8개의 항목 중 어떤 항목들이 Y냐에 따라서 WMO (Weak Memory Order), RMO (Relaxed Memory Order), TSO (Total Store Order), PSO (Partial Store Order) 등등 다양한 이름이 붙는다.
Summary
메모리 접근 연산이 일관성 있도록 (예측 가능한 범위에서 처리되도록) 하는 것을 메모리 일관성 모델이라고 한다. 현대적인 프로세서에서는 store buffer와 invalidate queue로 인하여 직관적이지 않은 순서로 메모리 연산이 처리될 수 있다. 따라서 다른 observer들에게 메모리 연산의 결과가 보이는 순서를 강제하려면 프로그래머는 메모리 모델을 숙지하고 적절한 상황에 메모리 배리어를 사용하여야 한다.
또한 알파 프로세서는 특이하게도 load-to-load address dependency를 이해하지 못할 수 있으므로 과거에는 데이터 의존성 배리어를 사용했어야했다. 최근에는 READ_ONCE()에 메모리 배리어를 추가해서 커널 코어에서는 알파 프로세서에 specific한 부분을 고려하지 않아도 되도록 바뀌었다.
다음에는 메모리 배리어와 의존성을 좀 더 자세하게 정리해봐야겠다.
References
[1] Memory Ordering in Modern Microprocessors, Paul E. McKenney
[2] Memory Barriers: a Hardware View for Software Hackers, Paul E. McKenney
[3] Linux Kernel Memory Barriers, Linux Documentation [English], [Korean]
[4] Linux Kernel 에서의 Memory Barrier 구현
[5] Dependent loads reordering in CPU, Stack Overflow
[6] Perf Book v2021.12.22a Paul E. McKenney
[7] Out-of-order execution, Wikipedia
'Kernel' 카테고리의 다른 글
| Page Cache: write (0) | 2022.03.09 |
|---|---|
| Page Cache: filemap_read (3) | 2022.02.09 |
| VFS: read_iter() & write_iter() (0) | 2022.01.24 |
| Direct Memory Access API (1) | 2021.12.29 |
| [Linux Kernel] 리눅스는 얼마나 작아질 수 있을까? (2) | 2021.12.05 |




댓글