NUMA: Non-Uniform Memory Access
메모리 관련 부분을 공부하다보니 NUMA가 많이 나와서 정리해본다. 이 글은 Christoph Lameter의 2013년 문서 "NUMA: An Overview"를 리뷰한 것이다.
NUMA는 멀티 프로세서 환경에서 메모리별 접근 속도가 프로세서에 따라 다른 접근 속도 가진 메모리의 형태를 말한다. 일반적인 PC에서는 메모리가 그렇게 많지 않아서 UMA (Uniform-Memory Access)가 많지만, 1990년대 즈음부터 고성능 컴퓨터에 대하여 NUMA를 적용한 컴퓨터가 나오기 시작했다.
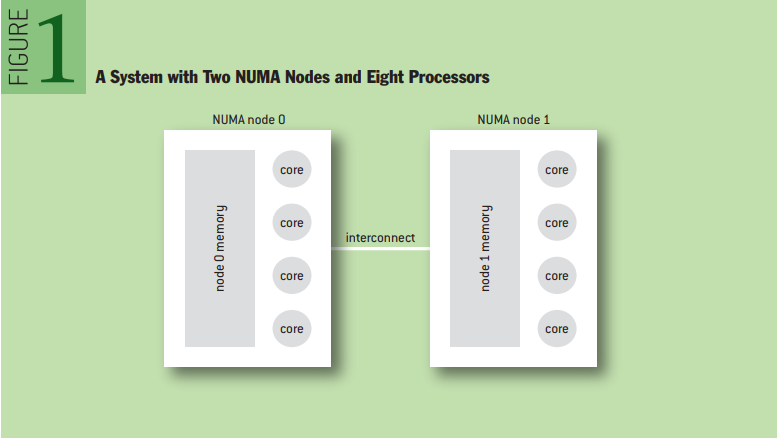
NUMA에서는 메모리를 노드라는 단위로 나누어지게 되는데, 프로세서마다 노드에 대한 접근 속도가 다르다. 아래 사진은 8개의 프로세서와 2개의 NUMA 노드로 이루어진 시스템을 그림으로 표현한 것이다. 아래의 예시에서는 왼쪽의 네 개의 프로세서는 node0에 대한 접근 속도가 node1에 대한 접근 속도보다 빠르며, node1에 접근하려면 interconnect를 통해 접근해야 하므로 node0보다 시간이 많이 소요된다.
기존(옛날)에는 운영체제가 UMA를 가정하고 만들어졌기 때문에 페이지 할당이나 슬랩 할당 요청에 대해서 아무 영역이나 할당해줘도 큰 문제가 없었는데, NUMA가 등장하면서 운영체제도 NUMA-aware하게 바뀌었다. NUMA 시스템에서는 가능한 한 프로세서에서 가장 빠른 노드로부터 메모리를 할당하는 것이 최적의 성능을 낸다. 반대로 속도가 느린 리모트 노드로부터 메모리를 할당받는 것을 최대한 피해야 한다. 2013년 문서기는 하지만 원문에 따르면 리모트 노드에 접근할 때 약 50%의 성능 저하가 있다고 한다. 이처럼 NUMA를 고려하여 메모리를 할당하는 것을 NUMA placement라고 부른다.
여기서 짚고 넘어갈 점은, NUMA를 고려하든 안하든 성능 이외에는 가시적인 영향이 없다는 것이다. 다시 말해서 NUMA를 그냥 무시해버려도 성능이 나빠질 뿐 크래시가 나거나 문제가 생기지는 않는다. 이런 점에선 캐시와 성질이 비슷하다.
NUMA-aware Operating System
자, 그렇다면 운영체제는 어떤 방식으로 NUMA에 대처해야 할까?
Just ignoring NUMA
위에서 말햇듯 NUMA의 특성을 무시해도 시스템은 잘 돌아간다. 노드별 성능이 별로 차이가 나지 않을 때는 큰 문제가 없지만, 차이가 많이 날수록 성능에 악영향을 끼친다. 또한 노드를 완전히 무작위적으로 접근하므로 성능이 일정하지 않고 시시각각 변할 것이다.
Memory striping in hardware
일부 시스템은 메모리 주소를 프로세서의 캐시라인에 매핑함으로써 특정 캐시라인에 해당하는 메모리는 특정 노드에 접접근한다. 각 노드를 균등하게 사용하므로 그냥 무시하는 것보다는 성능이 일정하게 나오지만, 최적의 노드를 사용하지는 않기 때문에 개선할 점이 존재한다. 특히 interconnect에 자주 접근하게 된다.
Heuristic method on application
이후에 자세히 설명하겠지만 운영체제에서 어플리케이션에게 휴리스틱 방법으로 메모리를 할당하면 좋은 성능을 보인다. 다만 NUMA를 고려해서 최적화하는 것이 노력이 많이 필요하기 때문에, 운영체제는 성능이 크리티컬한 부분만 NUMA를 고려해서 작성한다. 이때 운영체제에서 가장 많이 가정하는 것은 어플리케이션에게 로컬 노드의 메모리만 할당하는 것이 좋다고 생각하는 부분이다. 이 접근법은 어플리케이션이 로컬 노드보다 많은 메모리를 필요로 하거나, 스케줄러가 어플리케이션 스레드를 다른 프로세서로 마이그레이션하기로 결정했을 때 문제가 생긴다.
하지만 일반적으로 작은 어플리케이션에 대해서는 로컬 노드의 메모리만 할당한다는 접근법이 잘 작동한다. 다만 시스템 내의 메모리를 아주 많이 사용하는 어플리케이션에서는 NUMA의 이점을 살려서 최적화를 할 필요가 있다.
대부분의 Unix-style 운영체제는 이렇듯 NUMA를 고려한다. 특히 FreeBSD와 Solaris가 이러한 NUMA로 인한 병목 현상을 방지하는 솔루션을 갖고있다. FreeBSD는 라운드 로빈 방식으로 노드별로 일정하게 분배해서 성능 저하가 한 곳에 몰리지 않는다. 그리고 Solaris는 중요한 커널 데이터 자료구조를 노드별로 관리한다.
NUMA memory allocation policy
운영체제는 그냥 무작정 로컬 노드에서만 메모리를 할당해야 한다는 가정을 넘어서, 어떻게 메모리 할당을 노드에 따라서 분배할 것인지를 하나의 정책(memory allocation policy)으로 정함으로써 코드를 수정하지 않고도 시스템이 유연하게 대응하도록 할 수 있다. 이러한 정책은 튜닝 파라미터로 수정할 수 있다. 리눅스에선 taskset, numactl 등이 이를 위해 존재한다.
Application controls NUMA allocations
운영체제가 메모리 할당 정책대로 알아서 할당할 수도 있지만, 성능에 민감한 어플리케이션은 스스로가 NUMA 노드를 관리할 수도 있다. 따라서 운영체제는 시스템 호출로 특정 노드의 메모리를 요청할 수 있도록 한다.
About important kernel data structures
기본적으로 NUMA aware한 코드는 노드의 locality를 고려해서 작성하지만, 스케줄러가 관리하는 태스크 리스트처럼 시스템 전체가 공유하는 자료구조의 경우에는 이러한 locality로부터 이득을 얻을 수가 없으므로, 리모트 노드로 접근하는 성능 부하를 최대한 한쪽으로 쏠리지 않게 모든 노드에 이런 자료구조를 균등하게 분배하는 것이 최선이다.
How does linux handle NUMA?
리눅스는 메모리를 zone이라는 단위로 관리한다. non-NUMA 리눅스 시스템에서는 zone은 주소의 영역을 관리하는 데에서만 사용된다. (ZONE_DMA, ZONE_NORMAL, ZONE_HIGHMEM 등등) 하지만 NUMA 리눅스 시스템에서는 여러 개의 다양한 zone이 존재할 수 있다. 예를 들어서 Non-NUMA에서는 ZONE_DMA가 하나 뿐이지만, NUMA에서는 ZONE_DMA도 노드의 locality에 따라서 여러 개로 나뉠 수 있다.

Memory policies
위에서 말했듯 운영체제는 메모리 할당 정책 (memory policy)에 따라 메모리 할당을 관리할 수 있다. 이때 정책은 프로세스의 특정 주소 영역에 대해서만 적용할 수도 있고, 아니면 시스템 전체에 적용할 수도 있다. 무튼간에 주소로 범위를 지정할 수 있다.
여러 정책이 있지만 가장 중요한 것은 NODE LOCAL 정책과 INTERLEAVE 정책이다. 말만 들어도 알겠지만 NODE LOCAL 정책은 현재 프로그램이 실행되는 프로세서에서 빠른 노드에 메모리를 할당하는 정책이다. INTERLEAVE는 위의 FreeBSD 예시처럼 메모리를 여러 노드에 나눠서 분산 할당하는 정책이다. 이 정책은 시스템 전반에서 사용하는 커널 자료구조처럼 특정 노드에 한정되지 않는 데이터에 대해서 유용하다.
리눅스 기준으로 메모리 할당 정책은 부팅시와 부팅 이후로 나누어서 적용된다. 일반적으로 부팅할 때는 커널의 중요한 자료구조를 많이 할당하므로 INTERLEAVE 정책을 사용하고, 부팅 과정이 끝난 후에는 (정확히는 첫 번째 유저스페이스 프로세스인 init 데몬이 실행될 때) NODE LOCAL 정책으로 메모리를 할당한다.
리눅스에서 프로세스가 어느 메모리가 어느 노드에 할당되었는지 보려면 proc filesystem으로 확인할 수 있다. /proc/<pid>/numa_maps를 확인하면 된다.
Basic operations on process startup
프로세스는 자신의 부모로부터 메모리 할당 정책을 상속받는다. 따라서 기본적으로는 NODE LOCAL을 정책으로 한다. 따라서 프로세스가 생성되면 메모리는 해당 프로세서에서 제일 빠른 로컬 노드로부터 할당된다. 힙, 스택, mmap 메모리 등등 모두가 로컬 노드에서 할당된다.
또한 리눅스 커널의 스케줄러는 L1 cache의 cache-hotness를 유지하기 위해서 프로세스를 가능하면 다른 프로세서로 마이그레이션하지 않는다. 또한 스케줄링 시에 가능하면 L1 캐시, L2 캐시, L3 캐시를 공유하는 프로세스 순으로 스케줄링을 한다. 만약 스케줄링에 불균형이 생기면 스케줄러는 프로세스를 같은 NUMA 노드를 사용하는 다른 프로세서로 옮긴다.
다만 최악의 경우에 스케줄러는 다른 NUMA 노드로 프로세스를 마이그레이션한다. 그럼 이 프로세스는 실행되는 프로세서와 떨어진 리모트 노드의 메모리를 계속 접근하게 된다. 따라서 성능 저하가 발생한다.
그래서 최근에(2013년 기준) 스케줄러도 NUMA-aware하게 수정되었다. 수정된 스케줄러는 프로세스의 페이지를 다시 로컬 노드로 돌려주도록 바뀌었다. 이 기능은 3.8 이후에만 존재해서 성숙한 단계는 아니다. (다시 말하지만, 2013년 기준이다.)
Reclaim
리눅스는 메모리 요청이 들어오면 가능한 한 가용 메모리를 최대로 사용해서 할당해주려고 한다. 그렇게 함으로써 나중에 메모리에 할당한 내용을 다시 접근할 때 빠르게 접근할 수 있다. 하지만 메모리가 부족해지면 메모리를 덜 사용되는 페이지를 reclaim한다.(이걸 한국어로 뭐라고 번역할지 잘 모르겠다) 페이지를 더이상 사용하는 프로세스가 없으면 반납하고, 그게 아니라면 페이지를 디스크에 저장했다가 나중에 필요할때 다시 불러온다. (page swap)
IO 캐시로 사용되는 페이지가 아니라면 디스크에 저장해야 그 페이지를 다른 프로세스에게 할당해줄 수 있다. (당연한 말이다. 저장하지 않고 남한테 주면 데이터가 날아갈 것이다.) 하지만 몇몇 페이지는 플래그를 설정하여 reclaim이 불가능하도록 한다. (예를 들어 스케줄러의 태스크 리스트를 reclaimable하게 설정하면 상상도 하기 싫은 병목 현상이 생긴다.)
갑자기 reclaim 얘기를 해서 무엇이지 싶겠지만 NUMA의 특성이 reclaim에도 영향을 준다. NUMA 시스템에서는 노드마다 가용한 메모리의 크기가 다르다. 따라서 메모리 요청이 왔을 때 로컬 노드에서 해결할 수 없다면 커널은 두 가지 선택을 할 수 있다.
1. 로컬 노드에서 reclaim을 한다. (reclaim을 하는 데에 오버헤드가 존재함)
2. reclaim을 할 필요가 없는 리모트 노드에서 메모리를 할당해온다. (할당되는 메모리를 접근하는 데에 성능 저하가 존재함)
리눅스는 규모가 작은 NUMA 시스템(전형적인 2개 노드로 구성된 서버)에서는 두 번째 접근법을 기본으로 사용하고, 규모가 큰 NUMA 시스템에서는 (4개 이상의 노드가 존재하는 서버) 가능한 한 로컬 노드에서 reclaim을 하려고 한다.
/proc/sys/zone_reclaim에서 reclaim과 관련된 정보를 확인할 수 있다. 이 파일의 값이 0이면 로컬 노드에서 reclaim을 하지 않는다. 값이 1이면 로컬 노드에서 reclaim을 시도한다. 다만 zone_reclaim이 켜져있어도 커널은 reclaim을 최소화하려고 한다. 예를 들어서 reclaim을 하기 위해서는 매핑되지 않은 페이지가 특정 비율 (/proc/sys/vm/min_unmapped_ratio) 이상이 되어야 reclaim을 한다. 더티 페이지를 처리하거나 페이지를 스왑해서 더 적극적으로 reclaim을 할 수도 있지만, 그렇게 하면 성능이 나쁘기 때문에 잘 하지 않는다.
Basic NUMA command-line tools
주로 NUMA를 관리하기 위한 명령어는 numactl이다. numactl은 현재 사용되는 NUMA 설정을 보여주고, 노드가 어떻게 공유되는지를 컨트롤한다. 예를 들어 프로세스를 특정 프로세서, 특정 노드에서만 실행되게 제한할 수 있다. 아니면 노드 간의 태스크 마이그레이션을 피하거나 특정 노드에서의 메모리 할당을 제한할 수도 있다. 다만 이렇게 제한을 걸다보면 reclaim이 더 많이 발생한다.
또 다른 명령어는 taskset이다. taskset은 태스크를 특정 프로세서에서만 돌아가게 제한할 수 있다. taskset은 numactl보다 기능이 적다. taskset은 보통 non-NUMA에서 많이 사용되는데 그 인기때문에 NUMA에서도 이걸 사용하는 사람이 많 다.
NUMA information
시스템의 NUMA 특성을 확인하는 방법은 많다. 하드웨어의 특성을 확인하려면 numactl -hardware를 입력하면 된다. numactl -hardware는 SLIT (System Locality Information Table)의 덤프를 떠서 보여준다. 아래의 예시는 두 개의 NUMA 노드로 구성된 시스템을 보여준다. 로컬 노드에 대한 distance는 10이고, 리모트 노드에 대한 distance는 20으로 두배이다. 다만 실제로 정확히 distance가 10과 20이 아님에도 그냥 10과 20으로 보여주는 벤더도 있다는걸 주의하자. 그냥 차이가 어느 정도 나는지 가늠하는 데 사용하면 될듯 하다.

numastat은 메모리가 로컬 노드와 리모트 노드에 할당된 비율을 보여준다. numa_hit은 로컬 노드에 할당된 횟수를, numa_miss는 reclaim을 피하기 위해 리모트 노드에 할당된 횟수를 보여준다. other_node는 numa_miss를 포함하여 리모트 노드에 할당된 횟수를 보여준다. 아까 커널의 중요한 자료구조는 일부러 여러 노드에 걸쳐 할당한다고 했는데, 그건 의도적으로 리모트 노드에 할당한 것이므로 numa_miss에는 포함되지 않지만 other_node에는 포함된다.

프로세스에 대해 메모리가 어느 노드에 할당됐는지 보려면 /proc/<pid>/numa_maps를 확인하면 된다.

위의 사진은 메모리 주소 범위별로 정책을 보여준다. 사진에서는 모두 default (NODE LOCAL)로 되어있다. Anon은 페이지가 디스크 상의 파일과 관련이 없다는 것을 의미한다. NX=y는 각각 노드에 할당된 페이지를 보여준다.
특정 프로세스가 아니라 시스템 전체에서 메모리가 어떻게 할당됐는지 보려면 /proc/meminfo를 보면 된다.
First-touch policy
위에서 NODE LOCAL과 INTERLEAVE 정책을 알아봤다. 그런데 항상 어떤 메모리가 하나의 스레드만 사용하는 것은 아니다. 같은 프로세스에 속하는 스레드는 텍스트 세그먼트에 해당하는 페이지를 공유한다. 그런데 각 스레드의 NUMA 정책이 다른 경우에는 어느 정책을 사용할지가 모호하다. 이때 First-touch policy는 처음 그 페이지를 사용하는 스레드에 정책을 따르는 것을 의미한다. 따라서 처음 접근한 스레드가 NODE LOCAL이라면 그 페이지는 처음 접근한 스레드가 실행되는 프로세서의 로컬 노드에 존재할 것이다. 비슷하게 C 라이브러리도 많은 스레드가 공유하는데, 이것도 부팅할때 처음 해당 라이브러리를 실행한 스레드의 정책에 따른다. First-touch 정책을 적용할 땐 하나의 스레드만 메모리를 사용하지 않기 때문에 제약이 생긴다. (마음대로 다른 노드로 옮길 수 없다.) 만약 First-touch 정책으로 인해 지속적으로 성능 저하가 생기더라도 먼저 실행된 스레드에 정책에 따라야 한다.
Moving memory
리눅스는 프로세서 사이에서 프로세스를 마이그레이션하듯 노드 간의 메모리도 서로 이동할 수 있다. 이때 해당 메모리의 가상 주소는 그대로 유지하고 노드만 이동한다. 프로세스의 모든 메모리를 다른 노드로 마이그레이션 하는 것은 성능을 개선할 수 있다. 하지만 일반 사용자가 마음대로 로컬 노드를 잘 활용하고 있는 프로세스를 다른 노드로 이동하면 성능이 떨어질 것이다. 따라서 노드간 프로세스의 이동은 루트 유저만 할 수 있다.
이때 위에서 말했듯 프로세스들이 메모리를 공유하는 경우에는 모든 메모리가 로컬 노드에 존재하지 않을 수 있다. 특히 C 라이브러리나 공유 라이브러리처럼 많은 프로세스가 공유하는 메모리일 수록 이 문제가 크다.
리눅스는 migratepages라는 명령어로 특정 pid를 가진 프로세스를 source 노드로부터 destination 노드로 이동할 수 있다. 그러면 source 노드에 존재하는 페이지만 destination 노드로 이동한다.
NUMA scheduling
리눅스 스케줄러는 버전 3.8 전까지 NUMA와 관계없이 메모리를 할당했다. 프로세서간에 프로세스를 마이그레이션 하는것도 cache-hotness만을 기준으로 했지 NUMA 노드는 고려하지 않았다. 프로세스가 리모트 노드로 마이그레이션되면 지속적으로 리모트 노드에 접근하므로 성능에 매우 나쁘다. 3.8부터 스케줄러가 NUMA를 고려하게 되었지만 아직은 해야할 일이 많다. http://vger.kernel.org/와 http://lwn.net/에서 토론을 확인해보자. http://lwn.net/Articles/486858/
Conclusion
NUMA의 등장 이후 다양한 운영체제에서 이를 지원하기 위해 많이 수정되었다. 특히 리눅스는 2000년대 초부터 NUMA를 지원하기 시작했고 계속해서 수정되고 있다. 커널이 NUMA를 지원하면서 사용자가 개입하지 않아도 왠만한 NUMA 환경에서는 커널이 효율적으로 돌아가게 되었다.
다만 커널이 제공하는 NUMA 지원(휴리스틱 접근)으로는 부족한 경우에는 사용자가 numactl, taskset등의 명령어로 직접 조정할 수 있다. HPC 환경 (high-performance computing), 실시간 환경 (real-time) 등이 그 예시이다. 최근 들어서 엔터프라이즈급의 어플리케이션에서 NUMA 지원이 더 중요해졌다.
과거에는 NUMA를 지원하려면 깊은 지식이 필요했지만 어플리케이션과 하드웨어에 대한 특별한 지식이 필요했지만 리눅스의 NUMA-aware 스케줄러 등 다양한 시도로 인해 좀 더 쉽게 NUMA 기반 시스템을 활용할 수 있게 되었다.
NUMA 시스템은 가능한 한 성능을 향상하도록 사용해야 한다. 리모트 노드 접근 비용이 크면 클수록 NUMA placement가 중요해진다. NUMA latency는 메모리 접근에 의해 발생한다. 만약 어플리케이션이 메모리에 자주 접근하지 않으면 (대부분을 메모리가 아니라 캐시에 접근하는 경우)는 경우에는 NUMA 지원이 큰 의미가 없다. 또는 I/O 위주 어플리케이션에서는 메모리 접근보다는 I/O가 주된 병목 현상이므로 이런 경우에도 NUMA 지원이 큰 의미가 없다. NUMA를 지원하는 어플리케이션을 개발하려면 이런 하드웨어/소프트웨어적인 특성을 잘 이해해야 한다.
Further reading
McCormick, P. S., Braithwaite, R. K., Feng, W. 2011. Empirical memory-access cost models in multicore NUMA architectures. Virginia Tech Department of Computer Science.
Hacker, G. 2012. Using NUMA on RHEL 6; http://www.redhat.com/summit/2012/pdf/2012-DevDay-Lab-NUMA-Hacker.pdf
Kleen, A. 2005. A NUMA API for Linux. Novell; http://developer.amd.com/wordpress/media/2012/10/LibNUMA-WP-fv1.pdfLibNUMA-WP-fv1.pdf.
Lameter, C. 2005. Effective synchronization on Linux/NUMA systems. Gelato Conference; http://www.lameter.com/gelato2005.pdf
Lameter, C. 2006. Remote and local memory: memory in a Linux/NUMA system. Gelato Conference: SGI. Li, Y., Pandis, I., Mueller, R., Raman, V., Lohman, G. 2013.
NUMA-aware algorithms: the case of data shuffling. University of Wisconsin-Madison / IBM Almaden Research Center.
Love, R. 2004. Linux Kernel Development.
Indianapolis: Sams Publishing. Oracle. 2010. Memory and Thread Placement Optimization Developer’s Guide; http://docs.oracle.com/cd/E19963-01/html/820-1691/
Schimmel, K. 1994. Unix Systems for Modern Architectures: Symmetric Multiprocessing and Caching for Kernel Programmers. Addison-Wesley
원문
'Computer Architecture' 카테고리의 다른 글
| 다시 정리하는 NUMA (1) | 2022.01.21 |
|---|---|
| LEGv8 ISA - 특징과 명령어 포맷 (0) | 2021.12.02 |
| Instruction Set Architecture vs Microarchitecture (0) | 2021.12.01 |
| 메모리 계층별 대략적인 성능 비교 (0) | 2021.11.07 |
| The Elements of Cache Programming Style (0) | 2021.10.07 |




댓글