이 글은 1994년 Jeff Bonwick (Sun Microsystems)의 The Slab Allocator: An Object-Caching Kernel Memory Allocator를 정리한 것이다. 생각보다 오래 된 논문이다.
1. Introduction
슬랩 할당자는 1994년 Jeff Bonwick이 SunOS 5.4에 도입한 메모리 할당자이다. 이 메모리 할당자는 객체를 할당하고 해제할 때, 메모리를 할당하는 비용보다 생성/소멸시의 비용이 더 높으므로, 이런 생성/소멸 비용을 줄이고자 만들어졌다. 그리고 컬러링(colouring)을 통해 하드웨어 캐시를 최대한 활용하고자 한다. 또한 이 할당자는 통계와 디버깅 기능으로 시스템을 모니터링 하거나 시스템 상의 문제를 탐지할 수 있다. 또한 슬랩 할당자는 2, 4, 8, 16, ..., 이렇듯 2^n 단위로 기하학적 분포에 따라 할당하는 것이 아니라 정해진 크기 (sizeof(struct inode), sizeof(struct bio), ...등등)의 메모리를 할당하기 때문에 단편화를 줄일 수 있다.
2. Object Caching
오브젝트 캐싱은 자주 할당/해제되는 오브젝트를 관리하는 기술이다. 여기서 핵심 아이디어는 "처음 객체가 초기화된 상태"를 유지하는 것이다. 예를 들어 어떤 오브젝트에 뮤텍스가 존재하면 오브젝트가 생성될 때마다 매번 mutex_init과 mutex_destroy로 생성과 소멸 과정을 거쳐야한다. 하지만 오브젝트를 캐싱하면 이러한 비용을 줄일 수 있다.
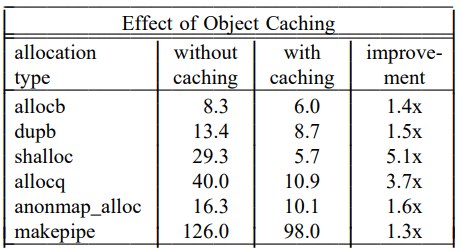
메모리를 할당하는 비용보다 오브젝트를 생성/소멸 하는 비용이 더 크기 때문에 캐싱은 중요하다. 예를 들어 SunOS 5.4에서는 아래 표처럼 생성 + 소멸 비용이 메모리 할당 비용보다 크게 나타났다.

오브젝트 캐싱은 특히 멀티스레딩 환경에서 유용한데, 멀티스레딩 환경일수록 lock 처럼 이런 초기화 비용이 많이 들기 때문이다. 근데 참고로, 시간이 지남에 따라 리눅스의 슬랩 메인테이너들은 이런 생성/소멸 비용이 그렇게 크지 않다고 판단해서 소멸자를 없애버렸다. 다만 생성자가 유용한 곳은 존재해서 남아있다.
Example
struct foo {
kmutex_t foo_lock;
kcondvar_t foo_cv;
struct bar *foo_barlist;
int foo_refcnt;
}foo라는 구조체를 예로 한 번 들어보자. foo는 foo_refcnt가 0이 되고, 또 foo_barlist가 비워지기 전까지는 해제될 수 없다고 해보자. 그럼 foo의 생애주기는 다음과 같을 것이다.

그럼 크게 (1) foo를 할당 및 생성하는 부분, (2) foo를 사용하는 부분, (3) foo를 해제 및 소멸하는 부분 이렇게 세 가지로 나뉜다. 오브젝트 캐싱을 함으로써 '(2) foo를 사용하는 부분' 이외의 나머지 두 부분은 오브젝트 캐싱에 의해 단 한 번만 수행된다.
The Case for Object Caching in the Central Allocator
어떤 서브시스템은 슬랩 할당자를 통하지 않고 각각의 서브시스템에 메모리 할당자(private allocator)를 구현할 수도 있을 것이다. 하지만 여기에는 몇가지 단점이 있다.
(1) 오브젝트 캐시는 더 많은 메모리를 사용하려는 반면, 운영체제 자체는 메모리가 부족할 때 reclaim하려고 한다. 하지만 운영체제는 private allocator의 존재를 모르기 때문에 private allocator로부터 메모리를 reclaim할 수 있다는 것을 알 수 없다.
(2) 슬랩 할당자를 통하지 않고 private한 캐시를 만들면 디버깅 기능이나 통계 기능을 사용할 수 없기 때문에 모니터링과 디버깅이 어려워진다.
(3) 한 문제(오브젝트 캐싱)에 대해 여러 개의 솔루션(여러 개의 private allocator)이 존재하는 것은 유지보수 비용을 높인다.
Object Cache Interface
(A) 오브젝트의 특성 (이름, 사이즈, 정렬, 생성자, 소멸자)은 API를 사용하는 쪽에서 정한다. (슬랩 할당자는 알 수 없다.)
(B) 메모리 관리는 슬랩 할당자에서 한다.

kmem_cache_create는 (A)에서 말하는 오브젝트의 특성을 서술한다. size는 오브젝트의 크기, align은 정렬 기준을 나타내고 0일 때는 정렬이 필요하지 않다는 의미다. name은 통계와 디버깅 기능에서 사용한다. constructor는 오브젝트를 (처음 한 번만) 생성하고, destructor는 오브젝트를 (메모리를 반환하기 전 한 번만) 소멸한다. kmem_cache_create는 캐시의 디스크립터를 반환한다.

kmem_cache_alloc은 캐시에서 오브젝트를 가져온다. 가져온 오브젝트는 생성이 완료된 상태이며, flags는 KM_SLEEP, KM_NOSLEEP 등 할당시 sleep을 할지를 명시한다.

kmem_cache_free는 오브젝트를 캐시로 반환한다. 이때, 반환하기 전 오브젝트는 반드시 오브젝트가 처음 생성된 상태를 유지하여야 한다.

kmem_cache_destroy는 캐시와 관련된 모든 리소스를 반환한다. 캐시를 삭제하기 전에 반드시 모든 오브젝트는 캐시로 반환되어야 한다.
Example
아래의 캐시를 생성하고 캐시로부터 메모리를 할당/해제하는 예시이다.


이때 슬랩 할당자는 constructor와 destructor를 kmem_cache_alloc/kmem_cache_free로부터 분리함으로써 프로세서의 인스트럭션 캐시를 더 효율적으로 사용할 수 있다.
3. Slab Allocator Implementation
이제 SunOS 5.4 커널의 슬랩 할당자를 다뤄보자. 여기서 "슬랩"이라는 말은, 슬랩 할당자 내부에서 사용하는 slab이라는 자료구조로부터 비롯되었다.
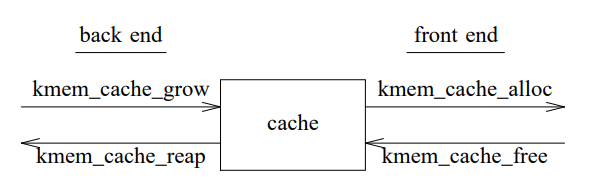
API 사용자에게 공개되는 frontend는 kmem_cache_alloc/kmem_cache_free로, 사용자는 메모리 할당과 해제만 생각하면 된다. backend에서는 필요에 따라 메모리를 관리한다. 이때 kmem_cache_grow는 메모리 서브시스템 (리눅스에선 buddy allocator)로부터 메모리를 가져와서 캐시의 크기를 늘리고, kmem_cache_reap은 시스템의 메모리가 부족할 때 슬랩 할당자가 사용하는 메모리의 일부를 다시 반환한다. backend는 메모리가 부족할 때 수행된다.
슬랩 할당자는 여러 개의 슬랩으로 이루어져있다. 그리고 각 slab은 서로 독립적이다. 각 슬랩이 독립적이기 때문에 per-cache locking으로 scalability가 좋아진다. (이때까지만 해도 커널 전체에 락을 걸거나, 힙 영역 전체에 락을 거는 등 투머치하게 광범위한 락이 많았다.)
캐시는 각자의 통계 데이터를 갖는다. 따라서 어떤 캐시에서 많은 할당과 해제가 이루어지는지 쉽게 모니터링할 수 있다.
또한 슬랩 할당자는 부팅시에 8바이트 크기에서 9K 크기를 갖는 캐시를 약 30개 가량 만든다. 이런 캐시는 임의의 크기에 대한 메모리 할당을 캐싱한다. 특정 사이즈에 대한 할당 요청이 들어오면 가장 가까운 크기의 메모리를 할당한다. 그리고 9K 이상의 메모리는 페이지 할당자로 할당한다. (이 부분은 리눅스 커널의 kmalloc/kfree와 동일하다. 실제로도 그렇게 만들어져 있다.)
Slabs
슬랩 할당자에서는 메모리를 슬랩 단위로 관리한다. 캐시의 크기를 키울 때는 슬랩을 더 만들고, 메모리를 반환할 때도 슬랩 단위로 반환한다. 이때 슬랩은 하나 이상의 물리적으로 연속된 주소를 갖는 페이지와, 얼마나 많은 오브젝트가 할당되었는지 나타내는 레퍼런스 카운트로 구성되어있다. 이렇게 슬랩 구조를 간단하게 함으로써 얻는 장점이 있다.
사용하지 않은 메모리를 반환하는 것이 쉽다.
슬랩의 레퍼런스 카운트가 0이 되면 슬랩을 반환할 수 있다. 따라서 coalescing이나 bitmap, tree 등의 복잡한 구조나 알고리즘이 필요하지 않다.
메모리의 할당과 해제가 상수 시간 안에 해결된다.
할당과 해제 시에서는 그냥 freelist에서 객체를 가져오거나 다시 넣고 레퍼런스 카운트를 갱신하기만 하면 된다.
외부 단편화가 심해지기 어렵다.
대부분의 메모리 할당자들은 시간이 지남에 따라서 사용 불가능한 영역이 생긴다. 이렇게 사용불가능한 영역은 할당자가 작은 메모리 할당 요청시 버퍼를 쪼갬으로써 생긴다. 예를 들어 32바이트 메모리와 40바이트 메모리를 계속 할당/해제하다보면 8바이트의 사용 불가능한 공간이 생긴다. 하지만 슬랩은 하나의 캐시에서 한 가지 사이즈의 오브젝트만 관리하기 때문에 이런 문제를 줄일 수 있다.
그리고 슬랩 할당자가 외부 단편화가 적은 또 다른 이유는 슬랩 내의 모든 오브젝트가 같은 타입을 갖고있으므로, 비슷한 생애주기를 갖기 때문이다. 비슷한 생애주기를 갖기 때문에 하나의 오브젝트가 슬랩 하나 전체를 일이 일어나기 어렵다.
내부 단편화를 최소화한다.
각각의 버퍼가 정해진 사이즈를 갖기 때문에 사용되지 않는 부분은 슬랩의 끝 부분이다. 예를 들어서 4K 크기의 페이지가 있고 오브젝트의 크기가 400 바이트라면 10개의 오브젝트와 96바이트의 남는 공간이 생긴다. 이때 2.4%의 내부 단편화가 생긴다.
일반적으로 슬랩이 n개의 버퍼를 갖고 있으면, 내부 단편화는 최대 1/n이다. 따라서 슬랩 할당자는 슬랩의 크기를 제어함으로써 내부 단편화를 제어할 수 있다. 오브젝트 크기가 커질수록 내부 단편화는 심해진다. SunOS에서는 내부 단편화가 최대 12.5% (1/8)까지 일어난다. 하지만 결국 내부 단편화와 외부 단편화 사이에서 트레이드 오프가 생기기 마련이고 이 12.5%가 그 사이에서 최적의 지점이라고 할 수 있다.
Slab Layout - Logical
슬랩은 kmem_slab이라는 자료구조로 관리된다. kmem_slab은 캐시 내의 슬랩을 링크드 리스트로 연결하고, 레퍼런스 카운트와 가용 버퍼를 관리한다. 이때 각 버퍼는 kmem_bufctl 자료구조로 관리된다. kmem_bufctl은 버퍼의 링크드 리스트, 버퍼의 주소, 그리고 이 버퍼가 소속된 슬랩의 포인터를 갖는다. 이를 사진으로 표현하면 다음과 같다.

Slab Layout for Small Objects
오브젝트의 크기가 1/8보다 작으면, 슬랩 디스크립터는 슬랩 데이터를 페이지의 마지막에 unused 부분에 놓는다. 그리고 그 외는 같은 크기의 버퍼로 사용한다.

각각의 버퍼는 kmem_bufctl과 대응된다. 이때 버퍼는 freelist에 있는 동안 그 자체가 bufctl의 역할을 한다. 오브젝트의 크기가 작을땐 이게 필수적인데, 이렇게 함으로써 kmem_bufctl을 따로 할당하느라 메모리를 낭비하지 않을 수 있다.
freelist 연결은 버퍼의 마지막에 존재한다. 왜냐하면 자료구조의 마지막보다 처음이 더 자주 접근되기 때문이다. 버퍼가 만약 해제된 이후에 접근되었더라도(use-after-free) freelist가 살아있어야 문제를 진단하기 쉽다.
그리고 슬랩 할당자는 오브젝트마다 하나의 워드 사이즈만큼 메모리를 예약해놓는데, 그래야 freelist가 오브젝트의 생성된 상태를 덮어쓰지 않는다.
Slab Layout for Large Objects
위의 구조는 오브젝트 크기가 작을 때는 효율적이지만 클때는 비효율적이다. 버퍼의 크기가 2K라면 슬랩 디스크립터 때문에 버퍼를 하나만 할당할 수 있게 된다. 게다가 슬랩이 order가 1이 아닌 페이지를 사용하면 슬랩 디스크립터의 주소를 계산하기도 불가능해진다. 따라서 오브젝트의 크기가 클 때는 아까 본 사진과 구조가 같아진다. (슬랩 디스크립터는 슬랩 외부에 존재한다.) 이때 kmem_slab과 kmem_bufctl을 위한 캐시는 따로 존재한다.
Freelist Management
각각의 캐시는 슬랩을 circular, double-linked list로 관리한다. 이때 슬랩 리스트는 전체가 사용중인 empty (이름 참 헷갈리게 지었다.) 리스트, 부분적으로 차있는 partial 슬랩 리스트, 아직 아무 오브젝트도 할당하지 않은 complete 슬랩 리스트로 관리된다. 캐시의 freelist 포인터는 첫 번째 non-empty 슬랩(부분적으로 사용중이거나 아예 오브젝트를 할당하지 않은 슬랩)을 가리킨다. 그리고 각각의 슬랩마다 가용한 버퍼의 freelist가 존재한다. 이렇게 freelist를 두 단계로 나눔으로써 freelist를 일일이 수정하지 않고도 메모리를 시스템에 쉽게 반환할 수 있다.
Reclaiming Memory
kmem_cache_free를 실행할 때 슬랩의 레퍼런스 카운트가 0이어도, 바로 메모리를 반환하지는 않는다. 대신 슬랩을 complete 슬랩의 tail에 연결한다. 이렇게 해서 complete 슬랩은 partial 슬랩이 다 차기 전까지 사용되지 않음을 보장할 수 있다.
시스템에 메모리가 부족해지면 슬랩 할당자는 최대한 메모리를 시스템에 반환한다. 메모리 반환 작업은 매번 실행되는게 아니라 15초마다 한번씩 반환한다. 측정 결과 이렇게 주기적으로 메모리를 반환하는 것이 성능에 크게 영향이 없음이 밝혀졌다. 아마도 두 극단적인 방법, 즉 매번 free할 때마다 슬랩을 회수하는 것과 아무것도 회수하는 것 모두가 최적은 아니기 때문이지 싶다.
4. Hardware cache Effects
현대적인 하드웨어는 캐시를 활용해서 성능을 최대화한다. 따라서 소프트웨어도 캐시를 고려해서 작성해야 한다. 메모리 할당자에서는 크게 두 가지의 캐시 효과를 고려해야 한다. 하나는 버퍼 주소의 분포이고, 나머지 하나는 슬랩 자체의 캐시 풋프린트이다. 후자는 기존의 논문에서 다루었지만, 전자는 지금까지 다뤄지지 않았다.
Impact of Buffer Address Distribution on Cache Utilization
중간 크기 버퍼의 주소 분포는 시스템 전체의 캐시 활용도에 영향을 미친다. 특히 오브젝트 사이즈가 2^n이거나 2^n으로 align되어있을 때는 캐시를 잘 활용하지 못한다. 예를 들어 오브젝트 크기가 512바이트이고, 512바이트 기준으로 정렬이 되어있다고 해보자. 그리고 이 오브젝트 첫 48바이트(sizeof(struct inode))만 자주 접근된다고 해보자. inode에 접근할 때는 주소가 항상 (0 ~ 47) % 512 사이에서만 접근할 것이다. 따라서 512바이트 중 9% (48/512)만큼의 캐시라인만 많이 사용하게 된다. fully-associative 캐시는 이런 문제가 없지만 너무 비싸서 사용되지 않는다. 최근에는 일반적으로 n-way set associative 캐시를 사용한다.

이렇듯 중간 크기(100~500바이트)의 버퍼를 할당하고 일부 필드를 자주 접근하는 것은 커널 자료구조에서 흔하다. 이러한 특징은 이전에는 종종 다뤄지지 않았다. 이 논문에서는 이런 버퍼 주소의 분포 문제를 컬러링(colouring)으로 해결하려고 한다.
Impact of Buffer Address Distribution on Bus Balance
프로세서가 여러 개의 메모리 버스를 사용하는 경우에는 버스 주소의 분포가 또다시 성능에 큰 영향을 미친다. 예를 들어 SPARCcenter 2000에서는 bus0과 bus1 2개 버스를 교차해서 256바이트씩 메모리에 접근한다. 이때 위의 예시에서는 항상 inode 부분만을 접근하므로 bus0에 치중하게 된다.
버스 균형의 영향은 생각보다 큰데, SPARCcenter에서 SunOS 5.4 커널로 LADDIS를 돌릴 때, 2^n 버디 할당자를 슬랩 할당자로 교체했을 때 버스 불균형이 43%에서 17%로 줄었고, 게다가 cache miss rate도 13%나 줄었다.
Slab Coloring
슬랩 할당자는 컬러링으로 버퍼의 주소를 분배한다. 방법은 간단하다. 슬랩이 생성될 때마다 버퍼의 시작 주소를 조금씩 다르게 (color) 하면 된다. 예를 들어서 200바이트 오브젝트 크기를 갖고 8바이트 기준으로 정렬하는 캐시가 있으면, 첫 번째 슬랩에서는 버퍼의 주소가 0, 200, 400, ... 이 될 것이고, 그 다음 슬랩에서는 8, 208, 408, ... 이 버퍼의 주소가 된다.
슬랩 컬러의 최댓값은 슬랩에서 사용되지 않는 메모리(unused)의 크기로 정해진다. 이 예제에서는 4K 페이지를 사용한다고 가정했을 때 20 * 200 = 4000 바이트가 버퍼에 사용되고, 32바이트가 kmem_slab에 사용되고, 나머지 64바이트를 컬러링에 사용한다. 따라서 슬랩 컬러의 최댓값은 64이고, 컬러는 0, 8, 16, 24, 32, 40, 48, 56, 64, 0, 8, 16, ... 이런식으로 반복된다.
컬러링의 장점은 2^n 형태의 중간 사이즈 버퍼가 원래 캐시를 잘 활용ㅎ아지 못하는데, 이러한 버퍼들이 오히려 컬러링을 최대로 활용할 수 있다는 점이다.
Arena Management
할당자의 메모리 관리 방식은 캐시 사용에 영향을 미친다. 이때 sequential-fit method, buddy method, segregated-storage method 세 가지 방법이 있다.
sequential-fit 할당자는 적절한 메모리 블럭을 찾느라 리스트를 순회해야 하므로 cache miss 뿐만 아니라 TLB miss도 많이 발생하게 된다. 그리고 buddy-system의 coalescing 단계도 비슷한 성질이 있다.
슬랩 할당자와 같은 segregated-storage 할당자는 버퍼 사이즈에 따라 freelist를 따로 관리한다. 따라서 cache locality가 좋고 버퍼를 할당하기가 매우 간ㄷ나하다. 할당자는 어떤 freelist에서 버퍼를 할당할지만 결정하고 거기서 할당하면 된다. 또 버퍼를 해제하는 것도 복잡하지 않다. 따라서 cache footprint가 작다.
그리고 슬랩 할당자는 작거나 중간 사이즈 버퍼에서 이점이 있는데, kmem_slab, kmem_bufctl, 버퍼 모두가 하나의 페이지에 존재한다는 점이다. 따라서 TLB miss가 줄어든다.
5. Performance
1994년 기준이긴 하지만 당시 유명한 세 가지 할당자와 슬랩 할당자를 비교해보자.
SunOS 4.1.3: Stephenson83, sequential-fit method;
4.4BSD: McKusick88, power-of-two segregated-storage method;
SVr4: Lee89, power-of-two buddy system method;
공평한 비교를 위해 각각의 할당자는 SunOS 5.4로 포팅되었다. 아래 사진을 보면 새로 도입된 슬랩 할당자의 할당/해제 속도가 가장 빠르다.

mutex_enter() / mutex_exit()의 비용이 1.0μsec이므로 락을 할당/해제하는 비용이 2μsec이다. slab과 4.4BSD 할당자가 가장 낮은데, 할당/해제시의 작업이 가장 단순하기 때문이다. 4.4BSD의 kmem_alloc 구현은 slab (kmem_alloc)보다 좀더 빠른데, 메모리 reclaim을 하지 않아서 더 할 일이 적기 때문이다. 하지만 slab (kmem_cache_alloc)이 더 빠른데, 어떤 cache를 사용할지를 찾는 수고가 더 적기 때문이다.
무튼간에 slab과 4.4BSD의 속도차는 그렇게 크지 않다. 왜냐하면 둘다 segregated-storage 방식이기 때문이다. SVr4 할당자는 buddy system이라 좀 느리긴 하지만 그래도 쓸만하고 성능을 예측할 수 있다. 하지만 SunOS 4.1.3 할당자는 sequential-fit 방식을 사용하기 때문에 매우 느리고 성능 예측이 잘 안된다.
위의 사진에서는 할당자의 성능만 측정하기 때문에 캐싱의 이점을 잘 보여주지 못한다. 아래 표는 SunOS 5.4 커널에서의 오브젝트 캐싱의 효과를 보여준다. (시간은 microsecond 단위임)
Memory Utilization Comparison
메모리 할당자는 완전 딱 맞는 크기를 할당하지 않기 때문에 내부 단편화가 생기고, freelist에서 사용하지 않는 객체도 존재하기 때문에 외부 단편화도 생기기 마련이다. 또 할당자 내부의 자료구조로 인한 오버헤드로 생긴다. 이때 요청된 메모리에 대한 실제 사용된 메모리의 비를 memory utilization이라고 한다. 비슷한 척도로 memory wastage와 total fragmentation이 있다. memory utilization이 좋아야 메모리를 효율적으로 사용한다.
근데 메모리 할당자가 메모리를 효율적으로 사용하는지를 판단하기는 쉽지 않은데, 환경에 따라서 달라지기 때문이다. 따라서 가장 좋은 방법은 고정된 환경에서 서로 다른 할당자의 utilization을 측정하는 것이다.
이때 네 가지 환경에서 메모리를 측정한다.
After system boot: 시스템 부팅 후
After spike: 아래 프로그램 실행 후

After Find: 아래 명령어 실행 후

After Kenbus: Kenbus benchmark 실행 후

마지막 열은 Kenbus를 실행시 수행된 분당 스크립트의 개수이다. (s/m)은 scripts per minute이다. 다만 여기서 알아둘 점은 Kenbus는 제한된 메모리 (16MB)를 갖는 시스템 안에서 수행되었기 때문에 SunOS 4.1.3이 좀더 느리긴 하지만 메모리를 더 효율적으로 썼다. 슬랩 할당자는 네 개의 할당자 중에서 가장 빠르면서도 공간을 효율적으로 사용한다.
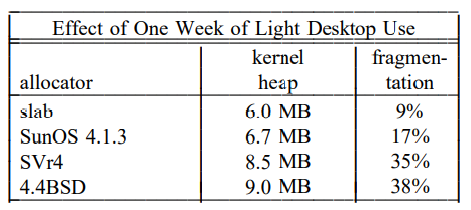
아래 표는 benchmark가 아니라 실제 사용에서 단편화를 관찰하기 위해서 1주일동안 사용 후에 단편화를 측정한 것이다.
Overall System Performance

커널의 메모리 할당자는 시스템 전체의 성능에 영향을 미친다. 위의 표는 SunOS 5.4 커널의 SVr4 기반 할당자를 슬랩으로 교채했을 때 얻는 성능을 측정한 것이다. 다만 DeskBench와 Kenbus에서는 메모리가 16MB로 제한되어있기 때문에 대부분의 성능 향상은 memory utilization 때문임을 알아두자.
TPC-B는 메모리 할당을 그렇게 많이 하기 때문에 할당자의 속도가 그렇게 중요한 요소는 아니다. 그리고 테스트가 매우 메모리가 큰 환경에서 실행되었기 때문에 utilization때문에 성능이 올라간 것도 아니다. 따라서 저 4%는 컬러링으로 인한 cache utilization 때문에 발생한 것이다.
Parallel make는 메모리 할당을 많이 하는 만큼 할당자의 영향을 많이 받는다. 여기서는 오브젝트 캐싱과 시스템 전체의 캐시 활용율 (5% 더 적은 primary cache misses, 4% 더 적은 secondary cache misses)로 이득을 본 것이다.
(5) Terminal server도 메모리가 충분한 환경 위에서 돌아간다. 이 환경에서는 기존에는 25%를 커널 공간에서 소모했지만 슬랩 할당자로 교체한 이후에는 20%만큼을 커널 공간에서 소모했다. 따라서 저 5%의 성능 개선은 커널 공간에서의 시간 시간 소모를 줄여서 나타난 것이다.
6. Debugging Features
종종 메모리와 관련해 코딩을 하다보면 실수를 하는 경우가 잦다. double-free, use-after-free, buffer-overflow, uninitialized variable에 접근 등등 다양한 오류가 발생하기 쉬운데 커널에선 그걸 디버깅하기가 어렵다. 운이 좋게도 슬랩 할당자는 디버깅 기능에 충실하다.
Auditing
audit mode에서 슬랩 할당자는 할당과 해제에 대한 로그를 기록한다. 다른 디버깅 기능으로 문제가 생기면 이 로그로 문제를 진단할 수 있다.
Freed-Address Verification
크기가 큰 버퍼에 대해서는 buffer를 bufctl로 변환하는 해시 테이블이 존재해서 잘못된 free를 탐지할 수 있다. 이때 "크기가 큰 퍼버의 기준"을 사이즈가 0이상인 버퍼로 정의해버리면 모든 슬랩 오브젝트에 대해 잘못된 free를 탐지할 수 있다.
Detecting Use of Freed Memory
오브젝트가 해제되면 슬랩 할당자는 소멸자를 실행하고 0xdeadbeef라는 패턴을 오브젝트에 기록한다. 그 다음에 오브젝트가 할당되면 슬랩 할당자는 0xdeadbeef가 그대로 존재하는지 검사해서 해제 후에 오브젝트를 사용하는지 검사할 수 있다. 사람이 읽기 쉽게 생성자를 실행할땐 0xbaddcafe, 소멸자를 실행할땐 0xdeadbeef를 기록한다.
Redzone Checking
redzone은 버퍼의 크기를 넘어서 데이터를 쓰는 것을 탐지할 때 사용된다. 각 버퍼의 마지막에 워드 크기의 빈 공간을 만들어서 버퍼를 해제할 때 이 redzone이 바뀌지 않음을 확인한다.
Synchronous Unmapping
위에서 언급했듯 일반적으로 슬랩 할당자는 아무 객체가 할당되지 않은 슬랩(complete slab)이 생겨도 당장 반환하는게 아니라 나중에 cache reaper를 통해서 반환한다. 하지만 Synchronous Unmapping 모드에서는 kmem_slab_destroy가 즉각적으로 슬랩을 반환한다. 슬랩을 즉각적으로 반환함으로써 잘못된 접근에 대한 오류를 더 잘 탐지할 수 있다.
Page-per-buffer Mode
이 모드에서는 버퍼마다 페이지 전체를 할당한다. 이렇게 하면 각각의 버퍼가 free된 후에 슬랩을 반환할 수 있다. 이 방법은 alignment를 페이지 크기로 설정해서 구현할 수 있는데, 근데 이건 왜 필요한거지??
Leak Detection
위에서 말한 audit 모드에서는 할당된 시간을 기록하는데, 오랫동안 해제되지 않는 메모리가 있으면 릭이 있다고 추측할 수 있다.
7. Future Directions
Managing Other Types of Memory
슬랩 할당자는 kmem_getpages, kmem_freepages로 메모리를 할당하는데, 이건 ram 상의 메모리가 아니라 다른 어떤 메모리여도 가능하므로 디바이스 메모리나 NVRAM 등에도 적용할 수 있지 않을까?
Per-Processor Memory Allocation
McKenney93의 할당자처럼 프로세서별 메모리 할당을 적용하면 lock contention이나 cache invalidation을 줄여서 성능을 향상할 수 있지 않을까?
User-level Applications
슬랩 할당자의 백엔드를 mmap이나 sbrk로 하면 사용자 공간에서도 구현할 수 있지 않을까?
8. Conclusions
슬랩 할당자는 심플하고 빠르고 메모리를 효율적으로 사용한다. 오브젝트 캐시 인터페이스는 복잡한 오브젝트를 할당하고 해제하는 비용을 줄이고, 오브젝트를 크기와 생애주기에 따라 분리한다. 슬랩은 이러한 분리를 통해 내부 단편화와 외부 단편화를 줄인다. 또한 슬랩은 메모리 reclaim을 간단하게 한다. 슬랩 할당자는 단순하게 가상메모리 시스템으로부터 메모리를 받아오고/다시돌려주는 관계를 가져서 reclaim시 복잡한 작업이 필요하지 않다. 또한 슬랩 할당자의 컬러링은 버퍼의 주소를 균일하게 분포함으로써 캐시를 효율적으로 사용하고 버스의 균형도 맞춘다. 슬랩 할당자는 몇가지 중요한 영역에서 눈에띄는 성능 향상을 보인다.
개인적인 생각
- 버디 할당자에서도 페이지의 주소 분포가 중요하지는 않을까?
- 생성자/소멸자는 정말로 요즘엔 이득을 보기 어려울까?
다음 글은 cache-friendly programming이나 Jeff Bonwick의 2001년 후속 논문인 Magazines and Vmem: Extending the Slab Allocator to Many CPUs and Arbitrary Resources이 되지 싶다.
'Kernel > Slab Allocators' 카테고리의 다른 글
| [Linux Kernel] SLUB 오브젝트 할당/해제 분석 (22) | 2021.10.24 |
|---|---|
| [Linux Kernel] slab_common 분석 (0) | 2021.10.10 |
| [Linux Kernel] SL[AUO]B: Kernel memory allocator design and philosophy (0) | 2021.10.05 |



댓글